

Group aggregation is widely used for large-scale data analysis (OLAP). Unlike regular
SELECT
GROUP BY
SELECT
SELECT
MobilePhone,
MobilePhoneModel,
COUNT(DISTINCT UserID) AS u
FROM
hits
GROUP BY
MobilePhone,
MobilePhoneModel
LIMIT
10;
Method
One intuitive approach is to process input data sequentially after sorting, with the best complexity being
O(nlogn)
O(n)
Our implementation draws inspiration from DuckDB's design, while introducing new optimizations for distributed environments.
New design
In the previous implementation, we first builds keys for grouping columns, then constructs hash values based on keys, and iterates through all rows to insert into hash table. This method is straightforward but brings several problems:
- Before probing, all grouping columns must be built into keys, which is a significant overhead when dealing with large amounts of data.
- Probing is performed row by row without utilizing vectorization.
- When the hash table needs to be resized, all data in the hash table needs to be moved out and then moved back in.
The new design addresses the above issues. Figure 1 is the architecture diagram.
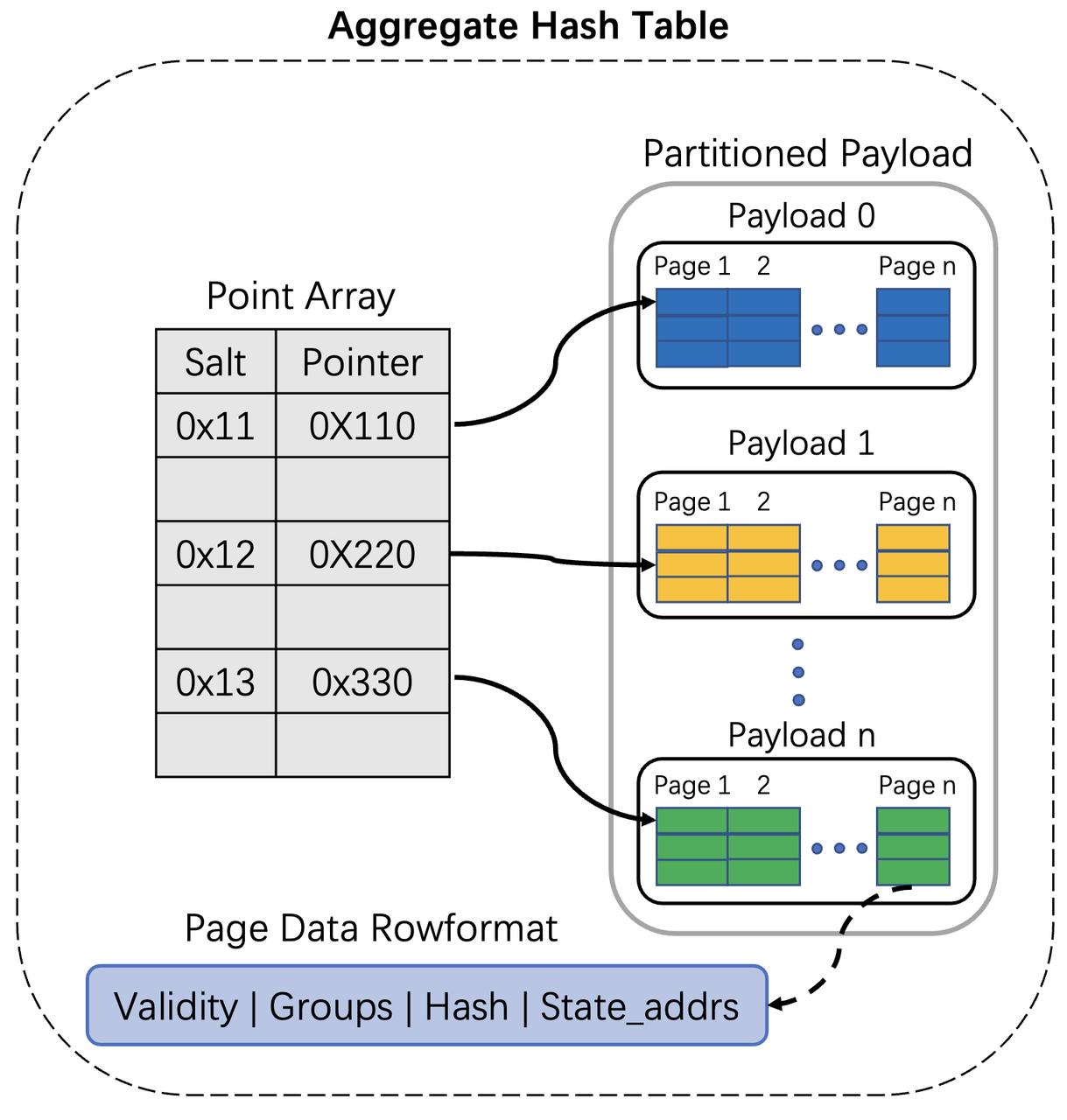
Figure 1: The Architecture Of The New Aggregate Hash Table
The new aggregate hash table includes two parts: Point Array and Payload.
- Point Array is a structure, and each u64 value represents an entry. Salt(u16) represents the high 16 bits of the group hash value, and the pointer(u48) points to the row address of the payload page data.
Vec<u64> - Payload actually holds the data of the hash table. Data is stored row by row in a fixed-length format within pages. Each page is a structure with a size of 256KB. Each row contains four members: Validity, Groups, Hash and Stateaddrs. Validity represents the validity bits of the grouping columns. Groups are group data, which could contain multiple values of fixed size, while strings are stored elsewhere. Hash is the hash value of the groups. State_Addrs represent the addresses of the aggregate functions (_8 bytes each). All payloads constitute a partitioned payload.
Vec<u8>
This two-level indexing structure has many advantages:
- Point Array is a PodType Array with a size of only u64, making access very friendly in terms of size and alignment.
- Before probing, there is no need to build keys and only the group hash needs to be built. Once the groups need to be appended into the payload, we build keys.
- Salt is the high 16 bits of the hash, and comparing salt in advance can significantly reduce the logic of key comparison.
- When the hash table needs to be resized, we simply scan all payloads to reconstruct the Point Array. There is no need to move the payload data, so the reconstruction cost is relatively low. Furthermore, in distributed environments, rebuilding the hash table only requires the payload. This allows the payload to be serialized to other nodes and then deserialized to reconstruct the hash table.
- In the Aggregate Partial stage, we don't need to rebuild the Point Array during resizing or repartition, we just clear the hash table and make sure it'll be merged in the Aggregate Final stage.
- The new aggregate hash table facilitates vectorized probe and vectorized combining of states.
Workflow
Above, we introduced the design of a new aggregate hash table. Now, let's discuss more about how it works. Figure 2 demonstrates the workflow, there are three primary operators: Aggregate Partial, Transform Partition Bucket, and Aggregate Final. And since we are operating in distributed environments, we introduce additional operators such as Aggregate Exchange Injector to ensure the even distribution of data across all nodes.
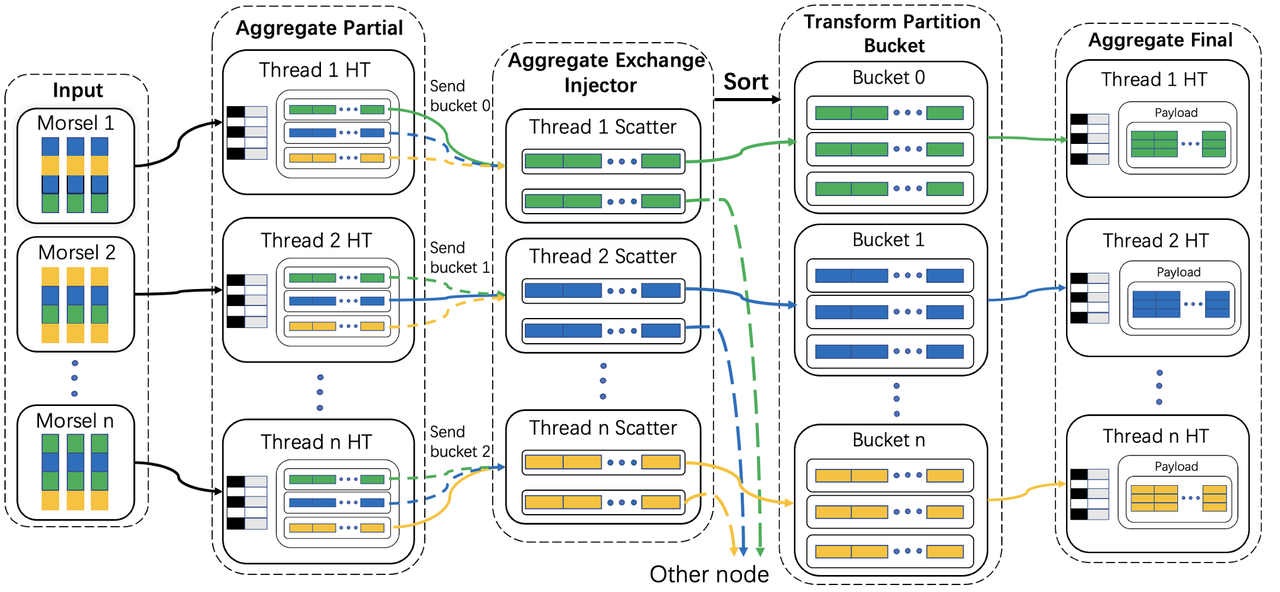
Figure 2: Workflow Diagram
Aggregate Partial
The upstream sends data to the downstream idle Aggregate Partial. During the Aggregate Partial stage, each thread independently constructs a thread-local hash table in two steps.
Step 1: Compute group hash(each column is hashed separately, and then the hashes are combined using XOR).
Step 2: Perform vectorized probe. First, we check whether the current hash table can accommodate this batch data. If not, we should resize the hash table first. Then, we calculate the entry offset based on the hash. If the entry is occupied, we compare the salt. If the salt is equal, we add the data index to the
group compare vector
empty vector
empty vector
group compare vector
In the Aggregate Partial stage, we also handle resizing and repartitioning. When the data in the hash table exceeds a certain threshold, we need to resize the hash table. At this point, we double the capacity and clear the point array, then we scan all payloads to reconstruct the Point Array. Additionally, because the size of each payload's page cannot grow indefinitely, so we repartition the partitioned payload by the radix bits once size exceeds a certain factor.
Aggregate Exchange Injector
This operator primarily scatters the data received from the upstream to ensure uniform distribution across all nodes. The Aggregate Partial operator can either transmit the entire partitioned payload or send individual payloads separately. We opt to send payloads individually to guarantee even distribution. Following the scatter process, the downstream operator is responsible for serializing the payload and forwarding it to the respective nodes.
Due to varying radix bits in each thread-local hash table, in distributed scenarios, ensuring transform partition bucket operator can correctly perform streaming merging requires upstream data transmission to maintain an ordered state. In the Aggregate Partial stage, We have ensured that buckets are sent monotonically to downstream. At this point, in the Exchange Sorting operator, we implement a multi-way merge sort based on the monotonicity of the input. Specifically, we calculate a unique block number for each bucket according to a formula(
block number = 1000 * radix_bits + bucket
Transform Partition Bucket
In this operator, we receive both payloads and serialized data from the upstream. For the serialized data, we first deserialize it into payloads. Then, we normalize all payloads to the maximum radix bits and classify them into buckets for further processing by the downstream Aggregate Final operator. As this operator needs to handle all data from the upstream, to alleviate potential blocking states, we use working and pushing buckets to ensure that upstream data is processed in a streaming fashion.
Aggregate Final
This operator needs to merge the data from the buckets sent by the upstream. We construct a hash table(
radix_bits= 0
Optimization
We have implemented several optimization strategies to improve the performance of the hash table:
- In the Aggregate Partial stage:
- We maintain an value, which is updated to the maximum value triggered by the thread-local hash table when repartition occurs. This ensures that subsequent repartitions of the thread-local hash table can directly expand to the maximum radix bits, reduce downstream normalization pressure.
Arc<atomic> max_radix_hint - We adopt dynamic resizing with an initially small capacity, and calculate a maximum capacity based on the number of threads and L1~3 cache. Before thread-local hash table reaching the maximum capacity, we resize continuously. Once the maximum capacity is reached, we no longer expand, but instead directly clear the point array. This ensures balanced performance for both low and high cardinality scenarios.
- We maintain an
- When sending data downstream during the Aggregate Partial stage, we do not send an entire partitioned payload. Instead, we treat each payload as individual buckets and send them one by one, recording the bucket value and radix bits of each payload to indicate whether normalization is needed. This approach has two benefits:
- In clusters, it ensures that data is evenly distributed to each node during scatter operations and also reduces serialization pressure.
- In standalone, downstream operators can determine the maximum radix bits for each input as soon as the first data is pulled, facilitating streaming processing.
- When deserializing payloads during the Transform Partition Bucket stage, no probing is required. Instead, data can be directly appended to the payload. Probes will be exectued in the Aggregate Final stage.
- Additionally, we support payload spills in both standalone and distributed environments, following a similar process as described in the workflow.
Experiments
We use
ClickBench/hits
Table 1: Performance Improvement Summary
| Query | Local Singleton (s) | Improvement | Local Cluster - 2 Nodes (s) | Improvement | Local Cluster - 3 Nodes (s) | Improvement | Cloud Small (s) | Improvement | Cloud Medium (s) | Improvement |
|---|---|---|---|---|---|---|---|---|---|---|
| Q13 | 1.081 → 0.881 | 19% | 1.652 → 1.416 | 14% | 1.995 → 1.417 | 29% | 0.722 → 0.533 | 26% | 0.838 → 0.686 | 18% |
| Q14 | 1.837 → 1.424 | 22% | 2.514 → 2.041 | 19% | 2.909 → 2.122 | 27% | 1.158 → 0.864 | 25% | 1.022 → 0.934 | 9% |
| Q15 | 1.279 → 0.983 | 23% | 1.876 → 1.536 | 18% | 2.270 → 1.563 | 31% | 0.817 → 0.603 | 26% | 0.885 → 0.711 | 20% |
| Q16 | 0.927 → 0.696 | 25% | 1.501 → 1.162 | 23% | 1.737 → 1.393 | 20% | 0.563 → 0.461 | 18% | 0.752 → 0.699 | 7% |
| Q17 | 3.030 → 1.620 | 47% | 4.154 → 2.631 | 37% | 4.361 → 2.934 | 33% | 1.714 → 1.049 | 39% | 1.435 → 1.047 | 27% |
| Q18 | 1.663 → 0.969 | 42% | 1.757 → 1.200 | 32% | 1.600 → 1.313 | 18% | 1.084 → 0.777 | 28% | 0.542 → 0.519 | 4% |
| Q19 | 6.223 → 2.737 | 56% | 8.269 → 4.699 | 43% | 9.316 → 5.060 | 46% | 3.326 → 1.872 | 44% | 2.515 → 1.642 | 35% |
| Q32 | 1.720 → 1.296 | 25% | 2.259 → 1.946 | 14% | 2.586 → 1.897 | 27% | 1.331 → 1.099 | 17% | 1.349 → 1.181 | 12% |
| Q33 | 9.633 → 3.772 | 61% | 13.700 → 7.863 | 43% | 19.029 → 8.305 | 56% | 4.258 → 2.322 | 45% | 3.620 → 2.352 | 35% |
Table 1: Performance Improvement Ratio
Summary
We were inspired by DuckDB and implemented an aggregate hash table to handle group aggregation. Furthermore, we added several optimizations tailored for distributed scenarios. Currently, it supports both standalone and distributed environments, and spill functionality has been implemented. Compared to the previously designed general hash table, the new aggregate hash table performs better when processing group aggregations.
Refercence
- https://clickhouse.com/blog/hash-tables-in-clickhouse-and-zero-cost-abstractions
- https://bohutang.me/2021/01/21/clickhouse-and-friends-groupby/
- https://hannes.muehleisen.org/publications/icde2024-out-of-core-kuiper-boncz-muehleisen.pdf
- https://duckdb.org/2022/03/07/aggregate-hashtable.html
- https://duckdb.org/2024/03/29/external-aggregation.html
- https://www.youtube.com/watch?v=INCPhRwC0EE
- https://github.com/databendlabs/databend/pull/15155
Subscribe to our newsletter
Stay informed on feature releases, product roadmap, support, and cloud offerings!

