


Slashing S3 Costs: How Databend Reduced List API Expenses by 70%
Databend, an open-source data warehouse, depends entirely on object storage services like Amazon S3 for data persistence. These services charge for API calls, and list operations can be particularly expensive. As our user base expanded, we observed a significant increase in our S3 costs, especially related to data spilling operations. This article outlines our efforts to optimize Databend's interaction with object storage, leading to a 70% reduction in S3 list API costs and notable performance enhancements.
The Hidden Cost of List Operations
As a S3-native modern data warehouse, Databend uses object storage (primarily S3) for data persistence. While storage itself is relatively cheap, the API calls - especially list operations - can quickly add up.
One of our enterprise users reported an alarming metric: their clusters were making 2,500-3,000 list requests per minute. Quick math: that's roughly 200,000 requests daily, translating to significant S3 API costs.
Understanding the Root Cause
The problem traced back to our spill mechanism - the process where Databend temporarily writes data to disk when it exceeds available memory. Our initial implementation was, frankly, naive:
- Create temporary files during spilling
- Use list_objects to find these files later
- Use list_objects again for cleanup
- Repeat this process for every query
Every time we needed to manage these temporary files, we'd make S3 list calls. It was like looking through your entire closet every time you needed to find a specific shirt.
From our observation, 60% of the S3 API calls are related to spilling list operations.
The optimizations
Our optimization journey focused on three major areas: introducing spill index files, redesigning the cleanup process, and implementing partition sort spill. Each of these optimizations addressed specific inefficiencies in our system while working together to create a more efficient overall architecture.
Spill Index Files: Efficient File Management
Managing spilled files using S3 list operations was costly and inefficient. To address this, we implemented a metadata tracking system with spill index files, formatted as
<queryid>_<node_id>.meta
Designed to be both lightweight and informative, the meta files can either be flushed immediately with a 4KB stream or retained in memory until the query is complete. This system enables precise file tracking without the need for costly S3 list operations. Queries can directly access these meta files to locate spilled files, bypassing the need to query S3.
Streamlined Cleanup Process
We revamped our cleanup system with two operational modes: QueryHook and VacuumCommand. QueryHook automatically cleans up after a query finishes, while VacuumCommand allows manual cleanup via the "VACUUM TEMPORARY FILES" command.
The cleanup process now primarily uses meta files for deleting files, resorting to traditional directory scanning only when necessary. This structured approach ensures efficient cleanup and system reliability. Additionally, parallel meta file fetching and optimized locking around unload_spill_meta operations significantly speed up the cleanup process.
Partition Sort Spill: Enhanced Data Management
Our most significant optimization involved rethinking data spilling. Previously, data blocks were spilled to storage immediately. Now, we buffer incoming data, sort it, and spill it in optimized partitions. Before:
Data Block → Immediate Spill → Storage
After:
Data Block → Buffer → Sort → Partition → Optimized Spill
The partitioning process starts with sampling data blocks to determine the best partition boundaries, ensuring even data distribution and minimizing partition numbers. The restore process is equally efficient, retrieving data in partition order to reduce unnecessary I/O operations. The Lazy Spill Implementation delays spilling to maximize memory use and cut down on unnecessary I/O operations.
Results
We tested these optimizations using TPCH SF_100 dataset with a customer ordering query on Databend Cloud XSmall Instance:
EXPLAIN ANALYZE
SELECT *
FROM customer
ORDER BY c_custkey, c_nationkey ignore_result;
-- Settings for the test
set max_threads = 3;
set sort_spilling_bytes_threshold_per_proc = 1024 * 1024 * 500;
| Metric | Before | After | Improvement |
|---|---|---|---|
| Execution Time | 124.6s | 60.2s | 52% |
| CPU Time | 51.68s | 25.60s | 50% |
| Wait Time | 201.06s | 67.79s | 66% |
| Spilled Data | 2.90 GiB | 1.21 GiB | 58% |
| Spill Operations | 965 | 411 | 57% |
On our cloud platform, once we applied those optimizations patches, the S3 api costs reduced by 70%, here is the screenshot from one of our test cluster: On Average, the list api request reduced by 70%, which greatly optimized the S3 api costs.
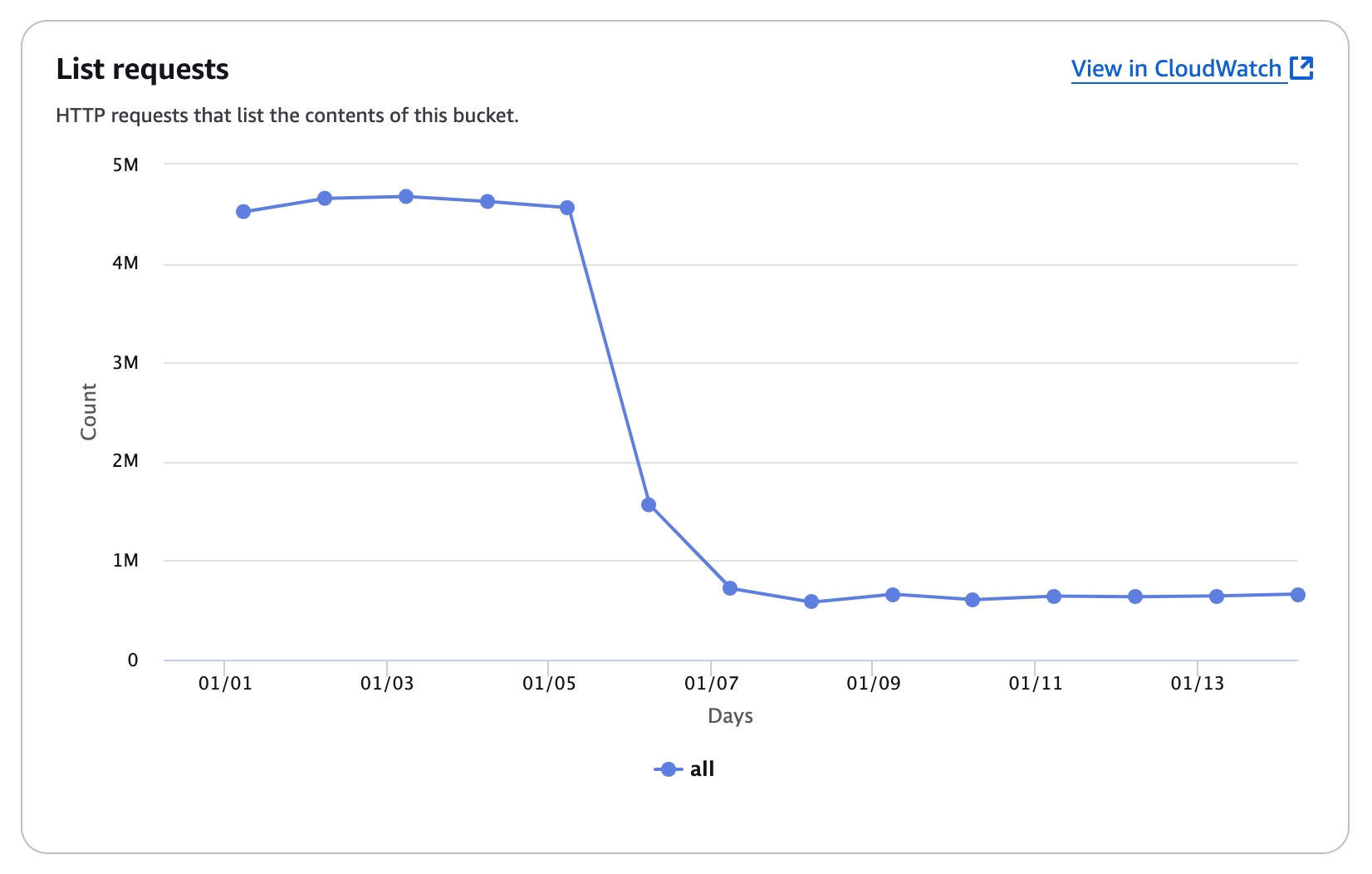
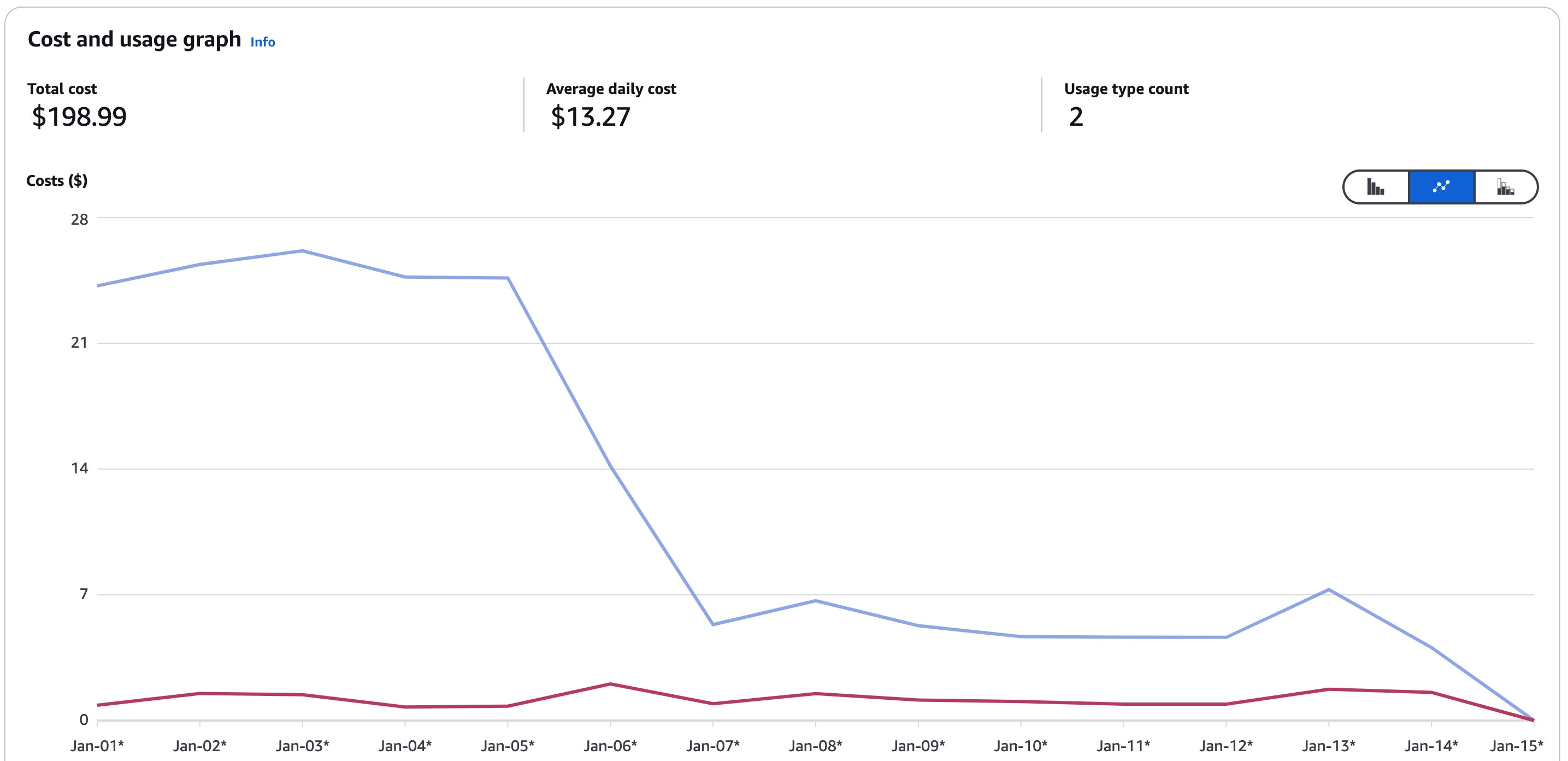
Conclusion
By implementing these optimizations, we've significantly reduced the number of S3 list operations, leading to a 70% decrease in S3 API costs. This not only improved our system's performance but also made Databend more cost-effective on both cloud and self-hosted platforms.
These optimizations are just the beginning of our journey to optimize Databend's interaction with object storage. We're committed to continuously improving our system and exploring new ways to optimize costs and performance.
Subscribe to our newsletter
Stay informed on feature releases, product roadmap, support, and cloud offerings!

