


The gaming industry is actually very close to money. Often, a game is expected to break even within six months after launch; if it doesn’t, the project might gradually be sidelined. This pace in the gaming industry, from a data production perspective, means generating hundreds of thousands of events per second, with tens of terabytes of data produced daily being the norm.
The gaming business has a wide range of needs, such as operations, gameplay, and economic layers. For example, a small traffic team of four or five people might need to allocate 1 million in traffic—can they recover that 1 million within this period? How should they analyze data over these few days? For such data analysis demands, relying on traditional dashboard displays is often impractical. In these cases, teams typically resort to direct SQL queries, exporting data to Excel sheets. Each flexible demand is handled this way, leading to an extremely high volume of analysis requests.
In addition, data engineers in the gaming industry often face a mountain of demands. They spend most of their time writing SQL, performing ad-hoc statistics, and exporting data for requests. Typically, they produce many Excel files daily, handling 30 or more tasks, sometimes even hundreds.
Under such immense demand, data governance in the gaming industry is extremely complex. On the data source side, it’s often divided into web games and client-based games, with client games further segmented into different mobile platforms like iPhone and Android, and Android split into various brands. How do users from these different brands and channels behave? What’s their user experience like? It even drills down to how the game performs on different screen sizes. Take the issue of game bitrate, for example—typically, you see data at 60 frames per second, and many games store every single frame of those 60, along with latency data for each interaction, to enable future optimizations.
Additionally, games incorporate "thrill and excitement" design elements. For instance, when a player defeats a monster, what rewards does the system provide? Can rewards be pushed in real-time after a player completes a task? Or, in a 15-minute match, how do you quickly match opponents for the next round to enhance the player’s experience and boost retention? How do you achieve real-time processing? After a match ends, how do you swiftly showcase the player’s highlight moments and game stats? These all pose significant challenges to real-time stream computing capabilities.
We once worked with a team whose game ranked in the TOP 10 on the iPhone charts. Their big data team had over 50 people, yet they still couldn’t keep up with all the business demands, with each request typically taking two to three days to resolve. This is very common in traditional big data teams and has become a standard business processing model. As a result, when facing rapid business iterations with traditional big data solutions, many companies find themselves in an even more chaotic situation. In real-world scenarios, you see countless Flink tasks flying around, with severe issues of task delays and queuing.
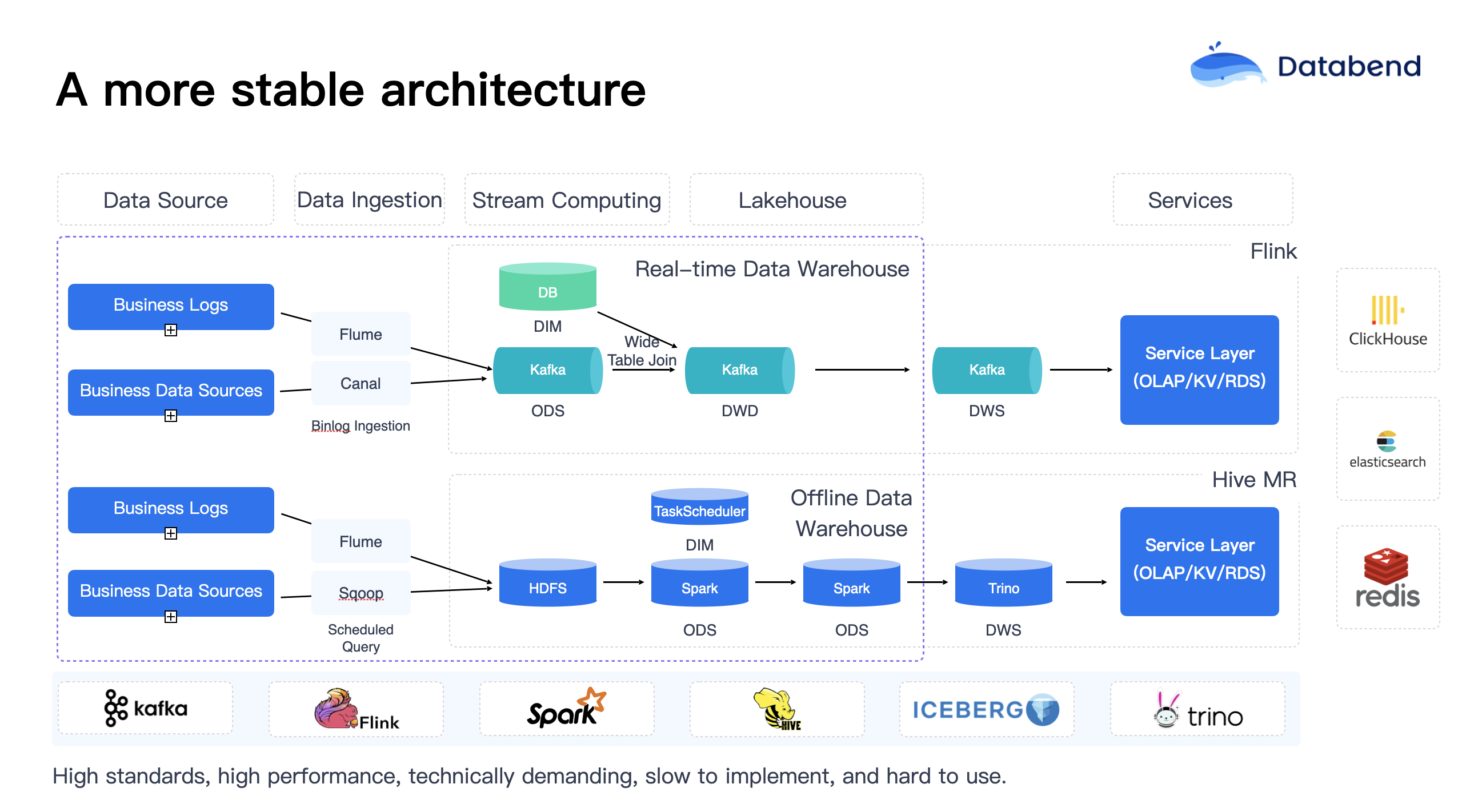
Many game companies’ early architectures faced similar situations. While it may seem like there are only a few components, the reality is far more complex than imagined. For example, behind a NameNode or directory service, there’s at least one MySQL database, and service availability discovery relies on ZooKeeper at minimum. These stacked components end up being far more numerous than initially anticipated.
Additionally, platform stability is a major challenge. Data transfer tasks often account for 80% of the workload. Data engineers frequently joke that they’re “data movers,” with their daily expertise lying in moving data from A to B, then from B to C, for aggregation, computation, and drill-down analysis. The platform’s computing resource bottlenecks are evident, and task queuing is a severe issue. MySQL databases are designed for high concurrency, capable of handling tens of thousands of concurrent requests at once, whereas traditional big data teams often endure tasks running slowly one by one, making the process extremely cumbersome.
Furthermore, one of the biggest issues with gaming platforms is the challenge of security. The platform incorporates a large number of stacked components, which may be very useful at the time, but if a security issue arises, it’s nearly impossible to pinpoint which component is at fault. If any part of the data pipeline fails, the entire data chain is dragged down. Therefore, in big data platforms, network isolation is a critical aspect that requires special attention. Another severe challenge is that if an IDC (Internet Data Center) fails, it often necessitates migrating to an external data center or setting up intra-city redundancy, which is an extremely troublesome process.
How to achieve a 10x revenue boost for data analysis in the gaming industry?
Databend’s current efforts have shifted from merely "storing" data to integrating with business scenarios, directly helping to improve business efficiency.
Massive Data: Ingested and Visible in Seconds**
First, Databend achieves massive data ingestion at the second level, which is distinctly different from traditional big data practices. Traditional big data focuses more on batch processing, typically with intervals of at least 5 or 30 minutes per batch. Databend emphasizes second-level data ingestion and enables real-time processing at every stage, ensuring data is visible in real time.
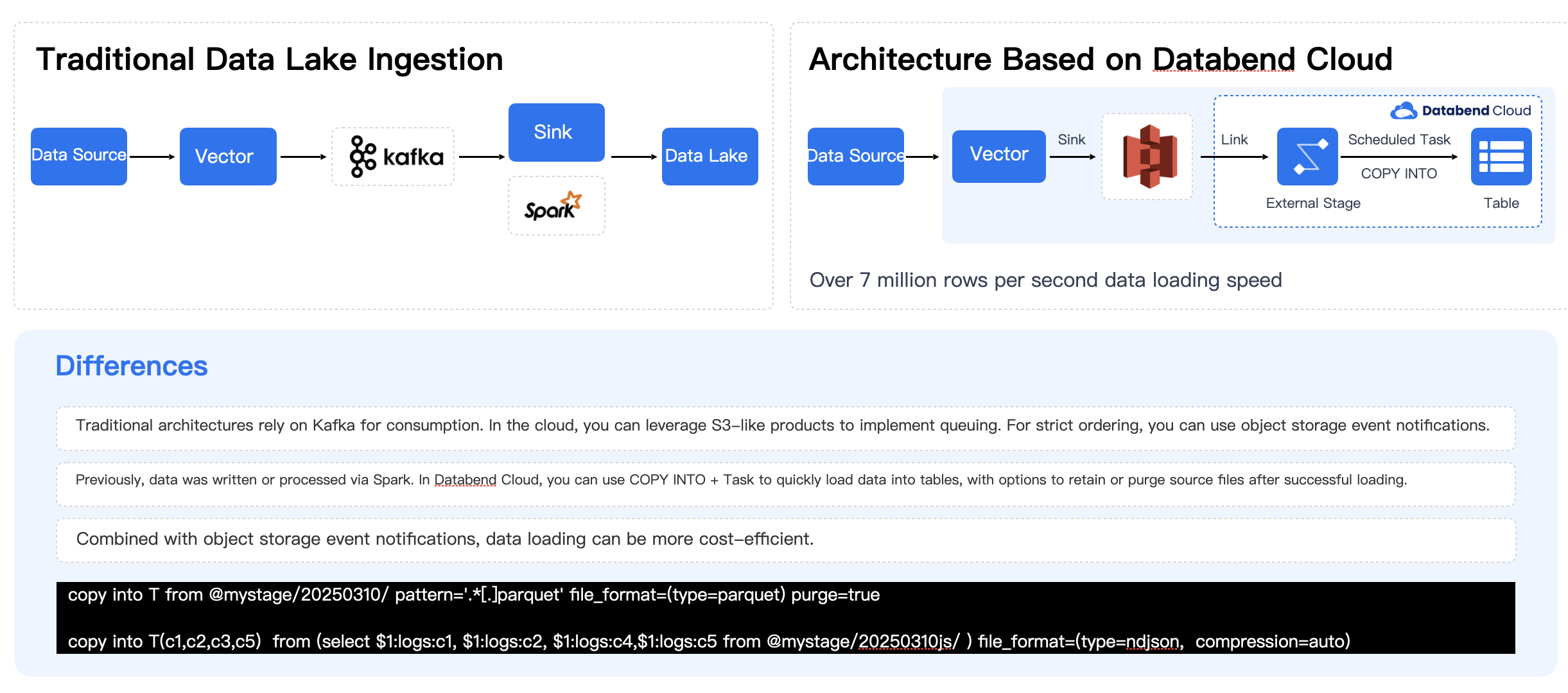
The left side of the diagram shows the data ingestion process in a traditional scenario, typically flowing from the data source to Vector, to Kafka, to Spark, and then to the data lakehouse. This pipeline appears clear at each stage, but the biggest issue is that every additional component in the cloud incurs a cost. Adding one more component means additional expenses and extra maintenance work.
Can the pipeline be further simplified? Is it possible to write directly from the data source to object storage? Can object storage replace Kafka’s role? For example, could multiple—or even hundreds—of applications write data directly to object storage? Once the data is written to object storage, Databend has a concept called External Stage, which allows linking to the specific location in object storage and directly invoking Databend’s COPY INTO command to quickly load the data into Databend tables.
Based on current testing, a standard cloud server can achieve an average data loading speed of approximately 7 million rows per second. This speed is typically limited by the bandwidth of the object storage and can generally saturate either the available bandwidth or the performance of a single node. During the loading process, Databend also supports data transformation. However, Databend adheres to the principle of minimizing transformations whenever possible—data should ideally be loaded in its original ODS (Operational Data Store) form. Subsequent processing can then be performed on the raw data, which also makes it easier to stay aligned with the source data.
In addition, Databend can take advantage of the event notification mechanisms provided by object storage itself. Users can subscribe to event notifications from the object storage, and when a file is generated via a PUT operation, the system can directly trigger a loading task—either through a webhook or a scheduling system such as Airflow—to quickly load the data into Databend.
In real-world scenarios, some customers still retain components like Flink and Kafka. For example, in collaborations with automotive companies or the IoT industry, it's common to encounter data in binary formats. Since Databend currently does not support direct processing of binary data, Flink is often used to convert such binary data into JSON or other structured formats before it can be ingested by Databend. At present, Databend supports formats such as CSV, TSV, NDJSON, JSON, Parquet, ORC, and Arrow, as well as their corresponding compressed variants. Essentially, Databend is capable of replacing the majority of Spark’s data processing tasks.
Therefore, in an ideal setup, users can eliminate both the Kafka and Spark stages, and simply align data directly via object storage. Of course, if your data format is irregular or you have special processing requirements, it is still advisable to retain the original preprocessing steps before loading the data.
Table-Level Change Data Capture for Incremental Computation
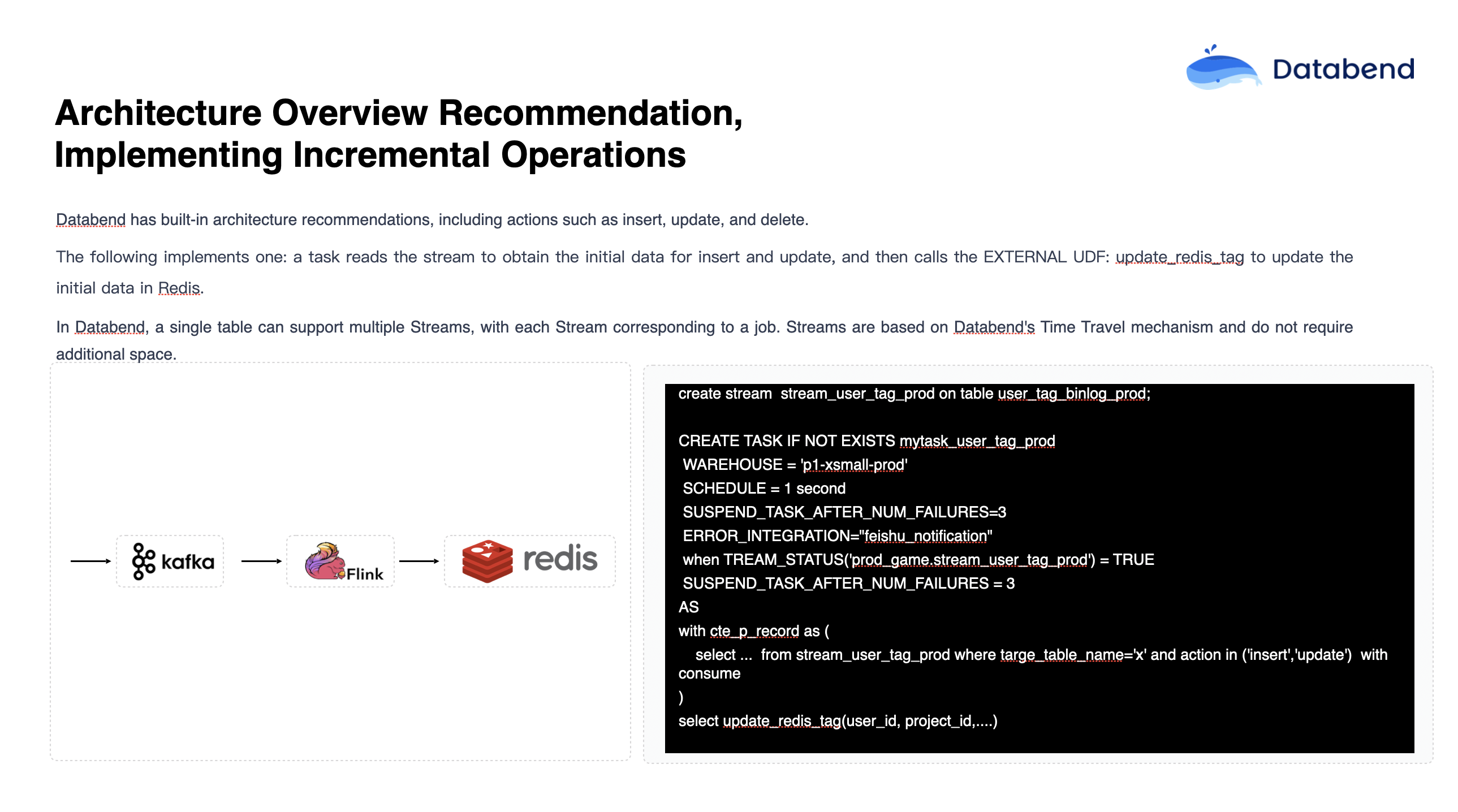
Earlier, we mentioned the real-time dashboard scenario in the gaming industry. Suppose a user finishes a game session and needs to immediately see an overview of their game data. Traditionally, this process involves ingesting data into a big data platform, processing it with Flink, and then writing the results into Redis or MySQL. This allows the game user to retrieve the relevant data directly from the database after the session ends.
In Databend, there's a feature called Table-level Change Data Capture (CDC), which records operations such as
INSERT
UPDATE
DELETE
Many users adopt this approach to write data into MySQL, other large lakehouse platforms, or Redis for serving external systems. This pattern has become a standard solution—gradually replacing traditional Kafka-based components with Databend’s native CDC capabilities, and substituting Flink processing with external UDFs.
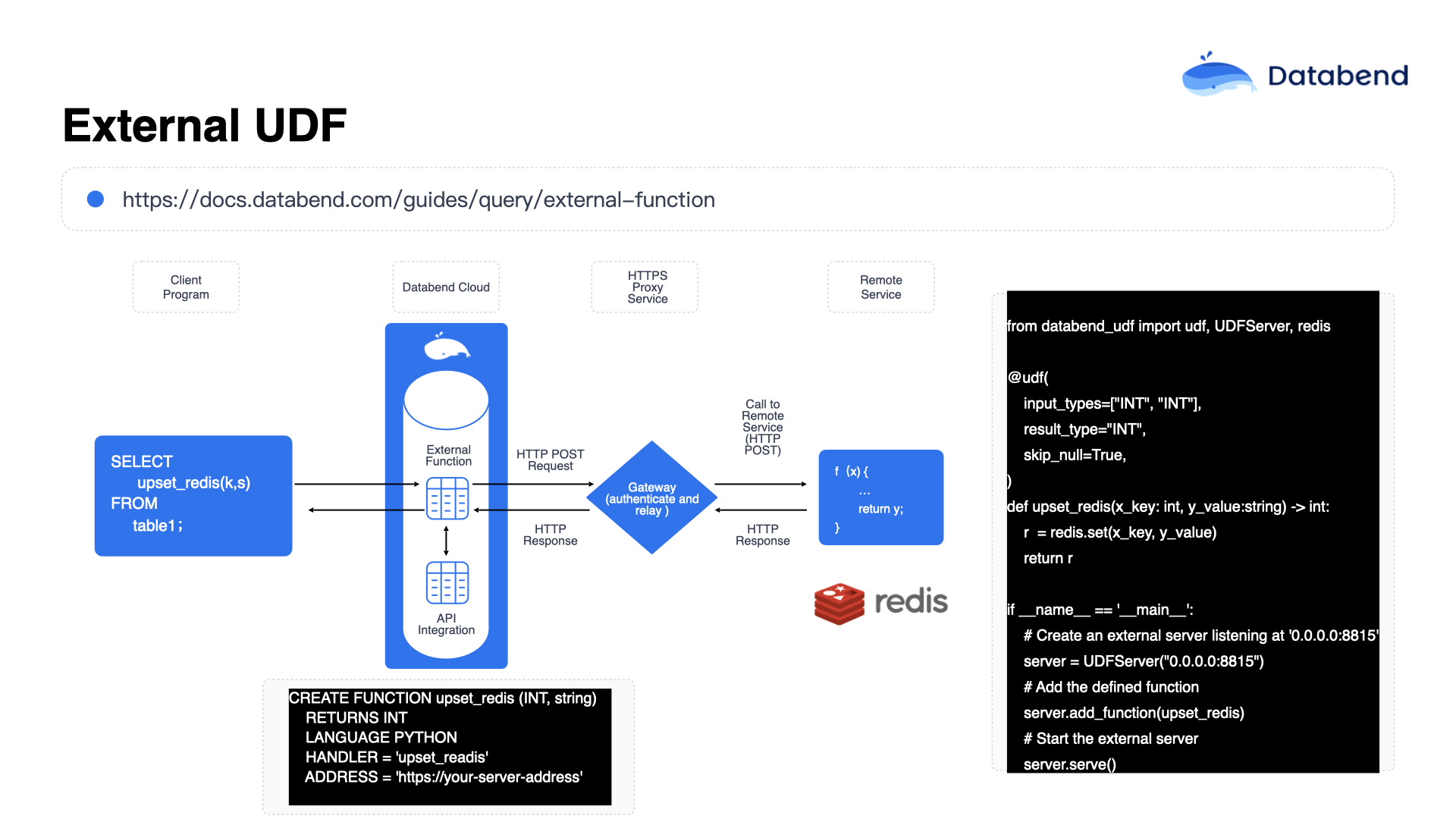
In the implementation of this feature, Databend also introduced some special handling: when invoking external UDFs, it batches the data into groups—typically around 100 rows per batch—for each UDF call. The reason for this design is that if your backend needs to process a very large amount of data at once—for example, 10,000 rows—passing all of it to a single UDF in one go can quickly create a performance bottleneck.
However, by processing data in batches of 100 rows per call, and assuming you have multiple UDF nodes deployed on the backend—say, 10 nodes—each node only needs to handle 100 rows at a time. This leads to faster and more efficient processing. If a performance bottleneck does occur, it can be mitigated by horizontally scaling out with additional UDF service nodes.
The overall architecture resembles a model where external Lambda functions can be attached and registered with Databend via an API Gateway, forming a unified set of external functions. With this registration and invocation mechanism, the system can achieve a calling frequency of approximately once per second. As a result, incremental data can be continuously and seamlessly pushed to the target system for real-time processing. This architecture also enables the implementation of complex algorithms and business logic, including both data processing and large-scale data presentation.
Building upon this, Databend has further extended its functionality by integrating AI capabilities. For example, you can encapsulate certain AI functions into callable functions, register them within Databend, and directly support use cases like similarity search, embedding vector computation, or even Text-to-SQL (natural language to SQL conversion).
Boost ETL Performance by 10× through Stream-Based Processing
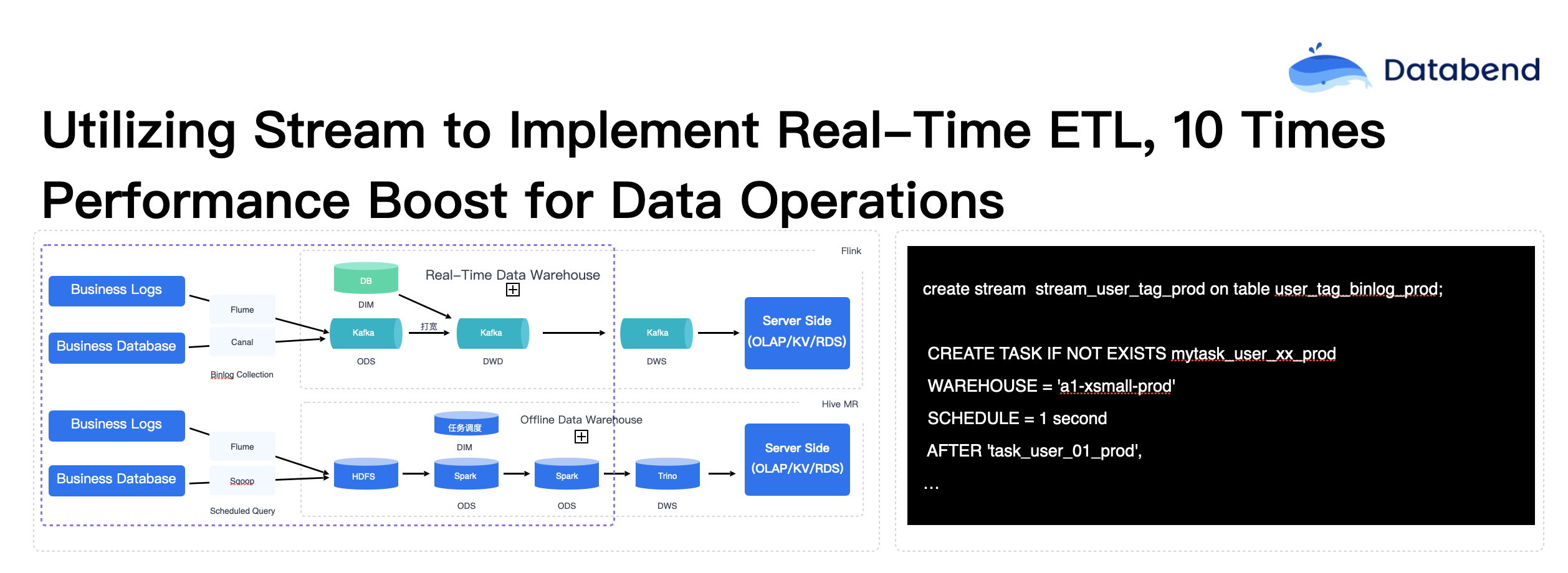
Traditional big data systems typically refer to the process as ETL, but within the Databend ecosystem, we prefer to call it ELT. This means that data is ingested in its raw form and then processed via internal tasks (Tasks) within Databend. For example, in traditional setups, binlog data is first ingested into Kafka, after which it is typically consumed in a passive manner. Databend introduces a different approach—binlog data can directly enter Databend, and Databend actively pushes the data out, creating a more proactive push mechanism. This approach leverages Databend's clear internal logging method (table-level change data capture) to simplify the architecture.
In this process, users can specify different compute clusters and clearly define which cluster should execute data processing tasks, including the scheduling frequency of these tasks, which can be defined by the user. The current smallest scheduling interval is 1 second (in contrast, Snowflake’s smallest scheduling interval is 1 minute). Databend achieves this second-level scheduling because, last year, we worked with some gaming industry users who required sub-second timeliness. If a task takes more than 1 second to run, an alert is triggered to notify the user to scale or optimize the system to ensure sub-second response times.

The diagram above shows the specific process of how Databend migrates data from the ODS layer to the DWD layer in an ETL scenario:
First, the data enters Databend in its raw form but needs to undergo deduplication. After deduplication, different processing logic is applied based on the specific type of data operation. For instance, using the
MERGE INTO
row_number
UPDATE
DELETE
INSERT
During the project implementation, an interesting scenario emerged: traditional big data teams usually prefer to perform DW layer data merging operations at night, i.e., processing a large amount of data in a unified manner overnight. However, it was later discovered that when the data volume is particularly large, it’s often impossible to complete the processing within one night. To address this issue, the data merging tasks are now broken down into smaller tasks with minute-level granularity, yielding great results. In large-scale projects, a single tenant may have millions of tables, and without breaking down the tasks more finely, many times the tasks cannot be completed within the limited time.
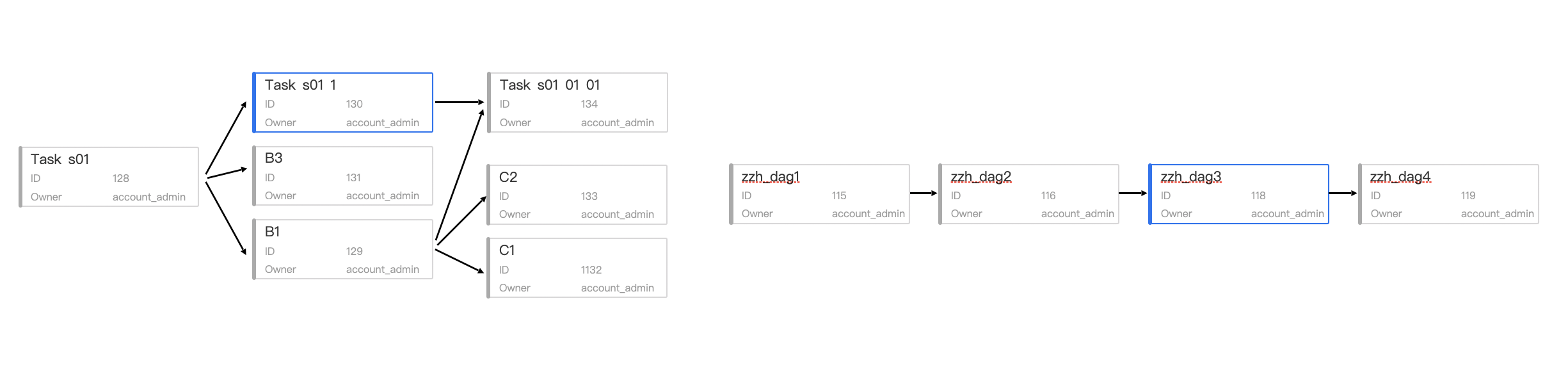
The diagram above shows the task visualization interface provided by Databend Cloud. For on-premises deployments, users can leverage tools like Airflow to achieve similar task visualization functionality. This type of functionality is relatively simple to implement and very intuitive to use. When an error occurs in a certain step of the task, the dependency status of the task is clearly displayed. For example, if there is a dependency between tasks, the subsequent tasks must wait until the previous ones are completed before they can run. This status indication, task scheduling, and error alerts displayed in red are all important details to pay attention to.

Databend has now expanded with many new SQL syntaxes, some of which are rarely seen in other databases, such as
MERGE INTO
INSERT OVERWRITE
INSERT Multi
INSERT Multi
Therefore, Databend introduced the
INSERT Multi
INSERT Multi
In addition, Databend supports directly reading CSV, TSV, NDJSON, Parquet, ORC, Arrow, and other format files from object storage using SQL. This functionality can largely replace the file processing tasks typically handled by Spark. Previously, similar products could only handle a single file, but Databend's design allows it to process a batch of files at once through regular expression matching, greatly improving data processing efficiency. Databend also specifically solves the idempotency issue during data loading: after a file is written into the corresponding table, it is not allowed to be written again within a certain time range (default is 2 days). If a repeat write is necessary, it can be forced by specifying certain parameters (such as the
force
Databend has also optimized complex
JOIN
JOIN
JOIN
JOIN
EXPLAIN
JOIN
How does a Data Analyst Work?
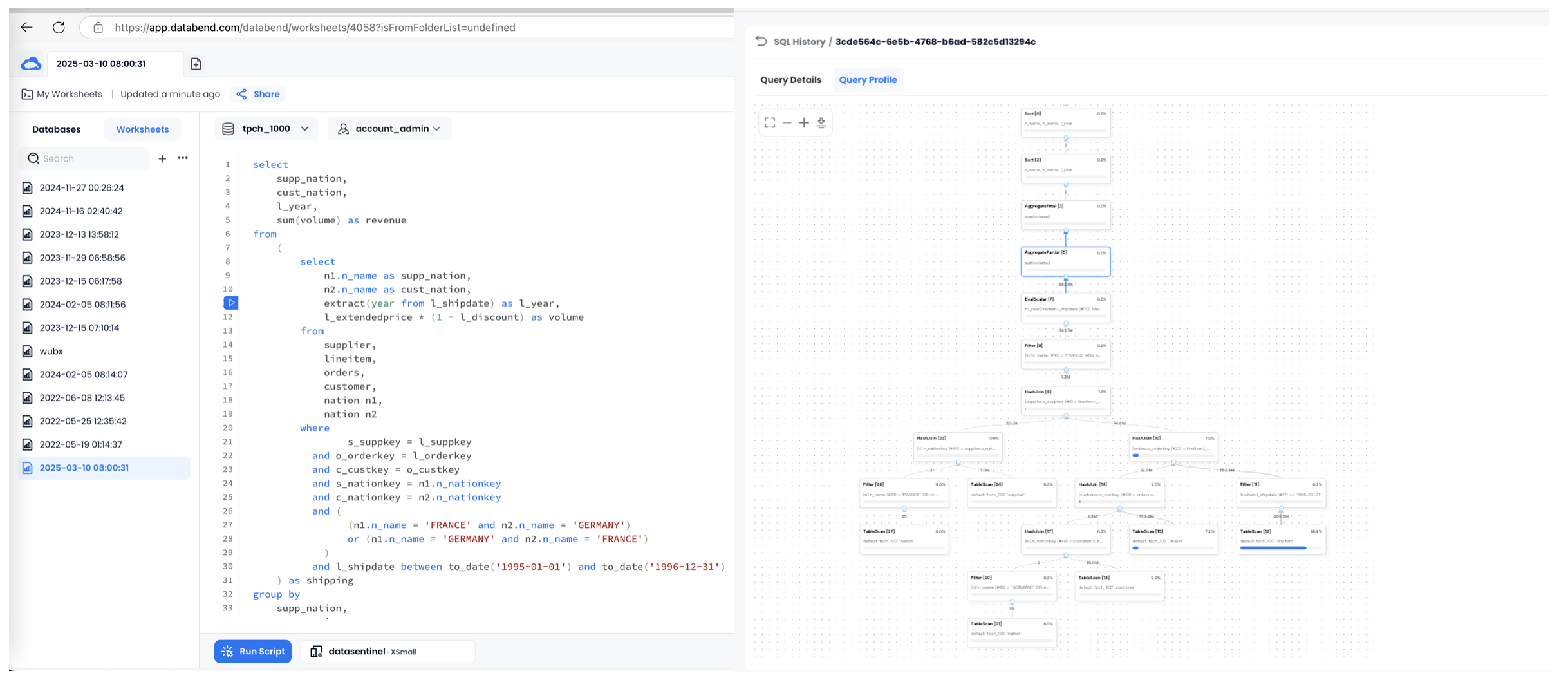
Databend Cloud provides a visual SQL IDE that also supports sharing. You can share SQL scripts with team members and collaborate with them within your group. Databend Cloud supports a Dashboard feature, allowing users to generate visual charts and displays through SQL.
Additionally, Databend offers a visual execution plan feature. With the execution plan, users can intuitively see the specific operators included in each SQL query and how much time each operator took. This helps users further optimize SQL query performance. This feature was developed in-house by the Databend team, so they have a deep understanding of the specific operators involved in the product and can display more detailed metrics. For example, when interacting with object storage, the response time for each step can be clearly displayed, allowing users to better perform performance analysis and optimization.
Excellent Features of Databend for the Gaming Industry
Databend has also made significant extensions in its foundational data types, adding support for types like bitmap and Array map. The Array type, in particular, has become a key feature that was previously not emphasized but is widely used in the big data field. For example, in the advertising industry, funnel functions are frequently used for retention analysis. This method enables easy calculation of user behavior paths, such as whether a user, after browsing the homepage, added a product to the cart, or whether they viewed a specific product. Such behavior analysis, and the ability to assess whether actions align with promotional expectations, can be easily achieved through the use of Array types and corresponding functions in Databend.
For complex SQL expressions, Databend also supports a Pipeline-style computation model, which allows for effective handling of intricate SQL operations. Overall, Databend’s goal is to ensure that as long as users know how to write SQL, they can perform any necessary data analysis operations within Databend.
Storage-Compute Separation Helps Users Achieve Greater Benefits
The concept of storage-compute separation is likely familiar to most, but the implementation of this architecture in Databend has advanced to a more sophisticated stage.
In Databend's approach, there are several aspects that differ from traditional big data products:
- No emphasis on partitions: Databend does not advocate for the use of partitions (Partition).
- No emphasis on indexing: Unlike many other systems, Databend does not place a heavy focus on creating indexes (Index).
- No strict data type requirements: Databend does not require users to meticulously choose data types, making it more flexible, even if a design includes non-standard types like .VARCHAR
- Support for non-standard data design: Even when users’ data design includes or other non-optimized data types, Databend can fully support them.VARCHAR
In industries such as government and mobile, the heavy use of
VARCHAR
Currently, Databend offers two types of Cluster Keys:
- Line Cluster Key: Based on sorting a single column using .Order By
- Hilbert Cluster Key: Based on sorting multiple columns using .Order By
By using Cluster Keys, Databend can significantly enhance query performance, especially for frequent queries targeting specific columns, improving the overall user experience in data service scenarios.
In the hybrid cloud scenario, Databend also enables a complete separation of compute and storage. For example, compute can be hosted on Databend Cloud, while data storage can remain in the user’s own Bucket storage. This architecture gives users greater flexibility. If users need to migrate their data out of the cloud, the process is straightforward since the data resides on the user’s premises.
In another case, if a company has internally deployed Databend but faces complex queries that require substantial compute resources, the company can register the data directly to Databend Cloud through the Attach feature. This allows them to leverage Databend Cloud's powerful compute capabilities to handle these complex analysis tasks while maintaining direct access to the data. Databend also provides High Availability (HA) solutions, and the overall deployment architecture is simple and efficient.
Databend Cloud redefines the separation of compute and storage
In the past, the term separation of compute and storage typically referred to the idea of having one layer for compute and a separate layer for storage. However, Databend has taken this concept further by creating a new paradigm. In this approach, compute is managed by Databend, where users interact with the SQL IDE, resource management, and resource scaling—all of these are handled by Databend. On the other hand, the data can be stored in the user's own Bucket storage.
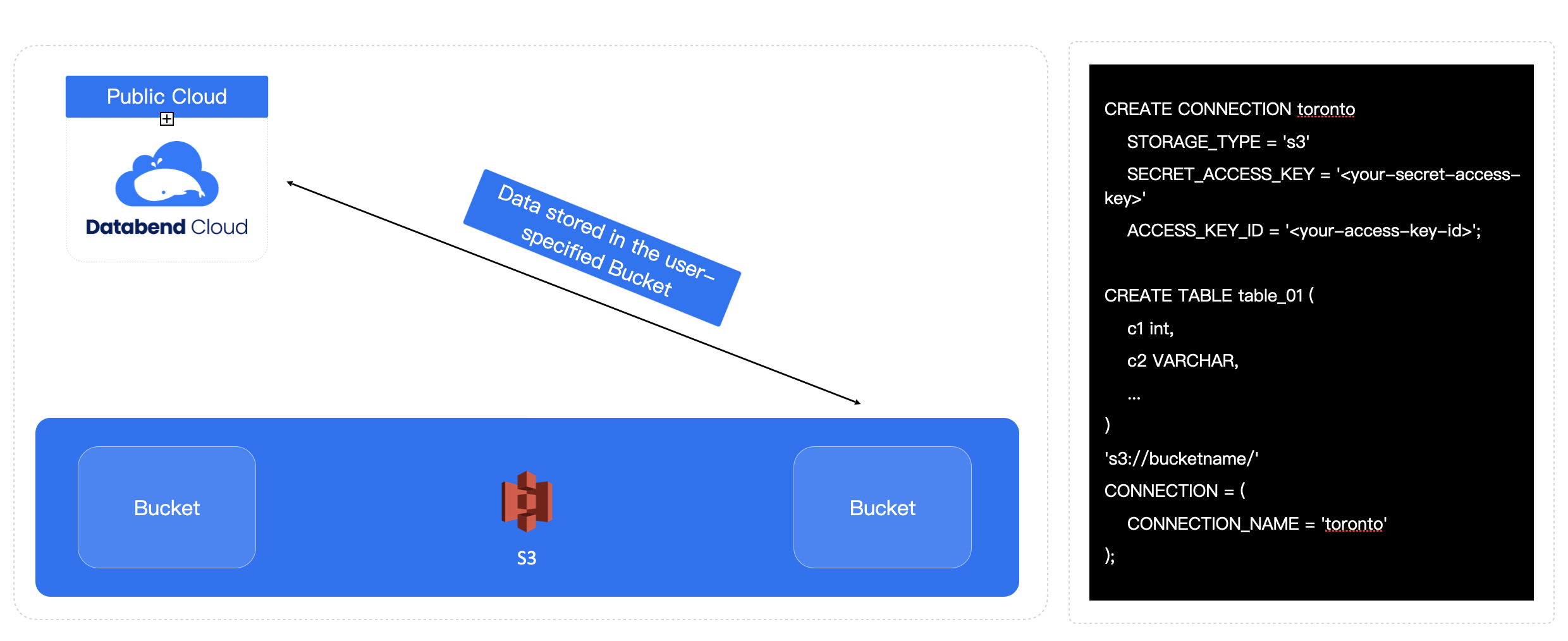
The specific implementation is also very simple. By creating a link to specify the location of the user's storage bucket, and then creating the corresponding table to associate with the data location in the bucket, the data can be directly used. In this model, users have come up with more creative solutions. For example, some users are very smart, placing their real-time business on Databend (because real-time business requires higher resource demands), with Databend Cloud handling the most recent real-time analysis needs. Meanwhile, they place their offline business in their own environment, as they have sufficient resources for offline computing.
In this model, data ingestion and real-time computing are handled on the Databend side, while data storage and offline computing are carried out in the user's own environment. Additionally, user-side data can be quickly mounted to Databend Cloud in a read-only manner and used directly, which brings great convenience to users. Another huge benefit of this model is that even if Databend Cloud itself experiences a serious failure or crash, the user's data remains stored on the user's side, unaffected. The data remains fully visible and can be quickly restored.
In 2023, a client in the short video industry adopted this model. The client had internally deployed a Databend instance for advertising and data analysis. Their CEO closely monitored the advertising data every day, and if any issues arose, they would immediately make a call. At the same time, they registered their core data on Databend Cloud, allowing the internal data analysis team and data scientists to freely perform more complex data analysis and exploration on Databend Cloud without affecting the company's core business systems. This way, the client only needed to focus on ensuring the data security and performance of the core business, while data analysis and mining tasks could be completed on Databend Cloud at a very low cost.
Additionally, Databend enables cloud-based internal data sharing and reuse through the Attach table method. This direct-read approach eliminates the need for the extensive data synchronization tasks commonly found in traditional big data systems.
Databend Cloud Multi-IDC High Availability
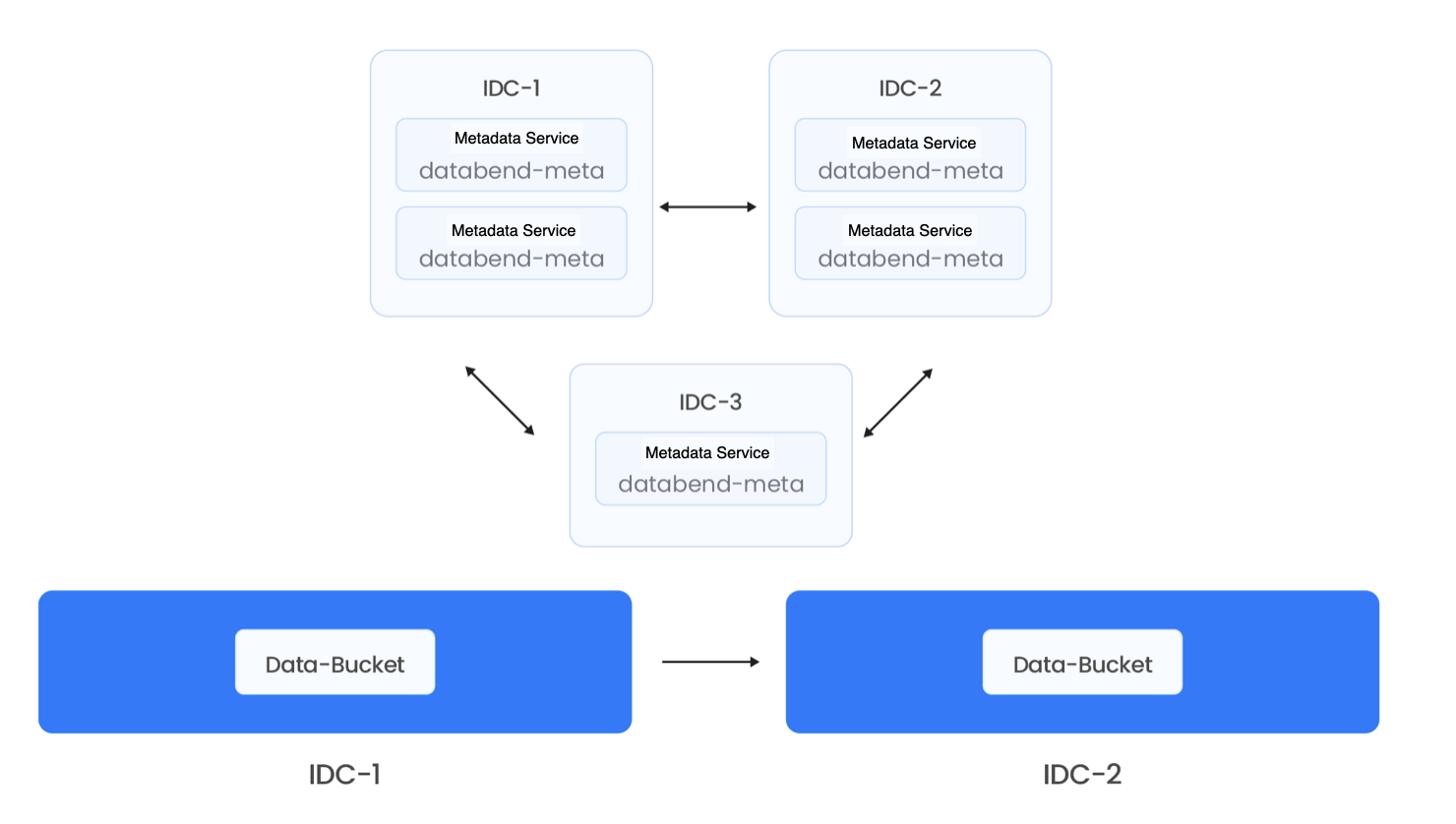
The high availability solution of Databend Cloud leverages a significant advantage of object storage in the cloud: when users purchase object storage, they can choose to replicate data between different data centers. This enables automatic data synchronization and high availability across multiple IDCs. The metadata layer, even with millions of tables and tens of millions of fields, has relatively small data size, making replication very easy. As a result, synchronization and replication between three nodes or even across three data centers is very simple and has low latency.
Currently, Databend is further exploring the possibility of storing metadata directly in object storage. This would allow metadata to be replicated directly between two object storage systems. As a result, computation nodes and metadata nodes would require minimal additional deployment, enabling users to more easily achieve rapid deployment and data replication across multiple IDCs. For example, after mounting a compute cluster in one data center, it can even be quickly brought up in a read-only mode and directly provide services. As long as data is not written to both IDCs simultaneously, it is entirely feasible. Unless bi-directional replication between the two object storages is also possible, true high availability for data writing across two IDCs can be achieved.
Subscribe to our newsletter
Stay informed on feature releases, product roadmap, support, and cloud offerings!

