


We're excited to bring you the latest updates, new features, and improvements for October 2024 in Databend! We hope these enhancements are helpful, and we look forward to your feedback.
Databend Cloud: Multi-Cluster Warehouses
A multi-cluster warehouse automatically adjusts compute resources by adding or removing clusters based on workload demand. It ensures high concurrency and performance while optimizing cost by scaling up or down as needed.
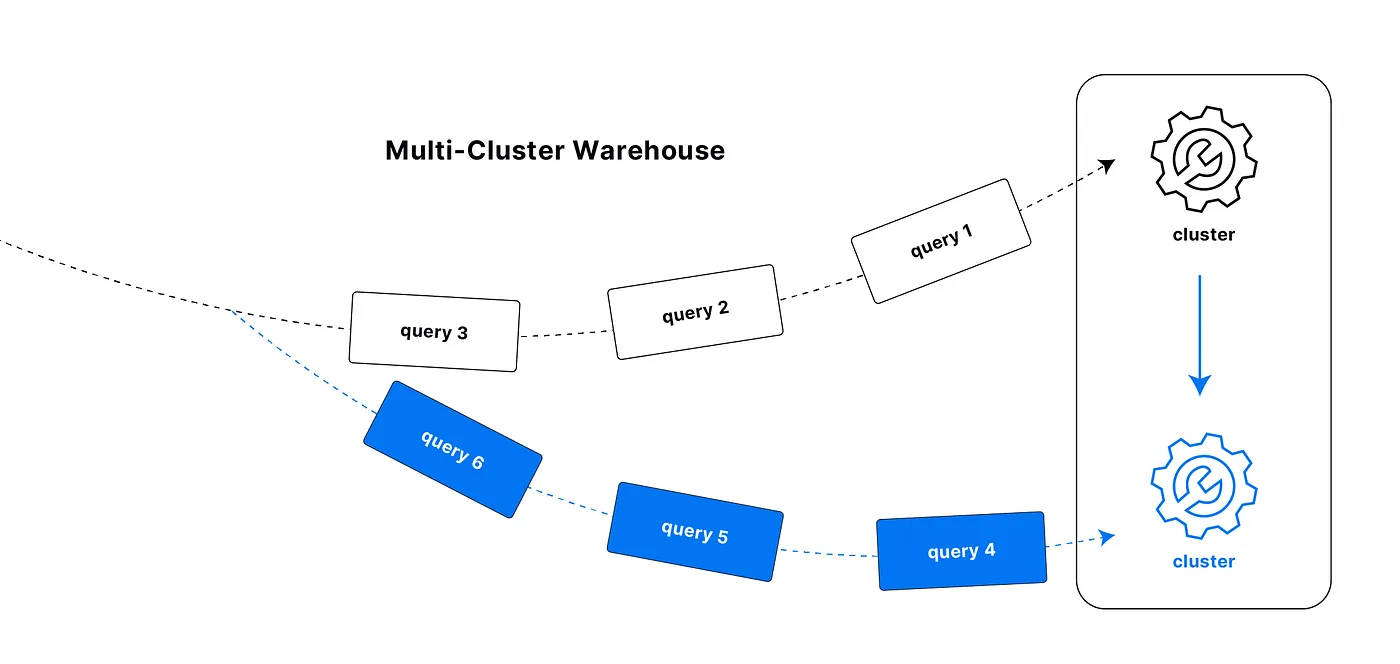
You can enable Multi-Cluster for a warehouse when you create it and set the maximum number of clusters that the warehouse can scale up to. For more information, see Multi-Cluster Warehouses.
Unsetting FUSE Engine Options
You can now unset Fuse Engine options for a table with the command ALTER TABLE OPTIONS, reverting them to their default values.
ALTER TABLE [ <database_name>. ]<table_name> UNSET OPTIONS (<options>)
ALTER TABLE fuse_table UNSET OPTIONS (block_per_segment, data_retention_period_in_hours);
SHOW CREATE TABLE fuse_table;
-[ RECORD 1 ]-----------------------------------
Table: fuse_table
Create Table: CREATE TABLE fuse_table (
a INT NULL
) ENGINE=FUSE COMPRESSION='lz4' STORAGE_FORMAT='native'
New Options for Data Unloading
New copy options have been introduced for the COPY INTO command:
- OVERWRITE: When , existing files with the same name at the target path will be overwritten. Note:
truerequiresOVERWRITE = trueandUSE_RAW_PATH = true.INCLUDE_QUERY_ID = false - INCLUDE_QUERY_ID: When , a unique UUID will be included in the exported file names.
true - USE_RAW_PATH: When , the exact user-provided path (including the full file name) will be used for exporting the data. If set to
true, the user must provide a directory path.false
Handling Invalid Date & Time Values
Databend automatically converts invalid Date or Timestamp values to their minimum valid equivalents,
1000-01-01
1000-01-01 00:00:00
-- Attempts to add one day to the maximum date, exceeding the valid range.
-- Result: Returns DateMIN (1000-01-01) instead of an error.
SELECT ADD_DAYS(TO_DATE('9999-12-31'), 1);
┌────────────────────────────────────┐
│ add_days(to_date('9999-12-31'), 1) │
├────────────────────────────────────┤
│ 1000-01-01 │
└────────────────────────────────────┘
-- Attempts to subtract one minute from the minimum date, which would be invalid.
-- Result: Returns DateMIN (1000-01-01 00:00:00), ensuring stability in results.
SELECT SUBTRACT_MINUTES(TO_DATE('1000-01-01'), 1);
┌────────────────────────────────────────────┐
│ subtract_minutes(to_date('1000-01-01'), 1) │
├────────────────────────────────────────────┤
│ 1000-01-01 00:00:00 │
└────────────────────────────────────────────┘
New Date Function: DATE_DIFF
DATE_DIFF calculates the difference between two dates or timestamps based on a specified time unit. The result is positive if the
<end_date>
<start_date>
SELECT DATE_DIFF(HOUR, YESTERDAY(), TODAY());
┌───────────────────────────────────────┐
│ DATE_DIFF(HOUR, yesterday(), today()) │
├───────────────────────────────────────┤
│ 24 │
└───────────────────────────────────────┘
New Aggregate Function: MODE
MODE returns the value that appears most frequently in a group of values.
SELECT MONTH(sale_date) AS month, MODE(product_id) AS most_sold_product
FROM sales
GROUP BY month
ORDER BY month;
┌─────────────────────────────────────┐
│ month │ most_sold_product │
├─────────────────┼───────────────────┤
│ 1 │ 101 │
│ 2 │ 102 │
└─────────────────────────────────────┘
New JSON Functions
We introduced a bunch of JSON functions to make handling and manipulating JSON data in Databend easier.
- JSON_ARRAY_DISTINCT: Removes duplicate elements from a JSON array and returns an array with only distinct elements.
SELECT JSON_ARRAY_DISTINCT('["apple", "banana", "apple", "orange", "banana"]'::VARIANT);
-[ RECORD 1 ]-----------------------------------
json_array_distinct('["apple", "banana", "apple", "orange", "banana"]'::VARIANT): ["apple","banana","orange"]
- JSON_ARRAY_EXCEPT: Returns a new JSON array containing the elements from the first JSON array that are not present in the second JSON array.
SELECT JSON_ARRAY_EXCEPT(
'["apple", "banana", "orange"]'::JSON,
'["banana", "grapes"]'::JSON
);
-[ RECORD 1 ]-----------------------------------
json_array_except('["apple", "banana", "orange"]'::VARIANT, '["banana", "grapes"]'::VARIANT): ["apple","orange"]
-- Return an empty array because all elements in the first array are present in the second array.
SELECT json_array_except('["apple", "banana", "orange"]'::VARIANT, '["apple", "banana", "orange"]'::VARIANT)
-[ RECORD 1 ]-----------------------------------
json_array_except('["apple", "banana", "orange"]'::VARIANT, '["apple", "banana", "orange"]'::VARIANT): []
- JSON_ARRAY_FILTER: Filters elements from a JSON array based on a specified Lambda expression, returning only the elements that satisfy the condition.
SELECT JSON_ARRAY_FILTER(
['apple', 'banana', 'avocado', 'grape']::JSON,
d -> d::String LIKE 'a%'
);
-[ RECORD 1 ]-----------------------------------
json_array_filter(['apple', 'banana', 'avocado', 'grape']::VARIANT, d -> d::STRING LIKE 'a%'): ["apple","avocado"]
- JSON_ARRAY_INSERT: Inserts a value into a JSON array at the specified index and returns the updated JSON array.
-- The new element is inserted at position 0 (the beginning of the array), shifting all original elements to the right
SELECT JSON_ARRAY_INSERT('["task1", "task2", "task3"]'::VARIANT, 0, '"new_task"'::VARIANT);
-[ RECORD 1 ]-----------------------------------
json_array_insert('["task1", "task2", "task3"]'::VARIANT, 0, '"new_task"'::VARIANT): ["new_task","task1","task2","task3"]
-- The new element is inserted at position 1, between task1 and task2
SELECT JSON_ARRAY_INSERT('["task1", "task2", "task3"]'::VARIANT, 1, '"new_task"'::VARIANT);
-[ RECORD 1 ]-----------------------------------
json_array_insert('["task1", "task2", "task3"]'::VARIANT, 1, '"new_task"'::VARIANT): ["task1","new_task","task2","task3"]
-- If the index exceeds the length of the array, the new element is appended at the end of the array
SELECT JSON_ARRAY_INSERT('["task1", "task2", "task3"]'::VARIANT, 6, '"new_task"'::VARIANT);
-[ RECORD 1 ]-----------------------------------
json_array_insert('["task1", "task2", "task3"]'::VARIANT, 6, '"new_task"'::VARIANT): ["task1","task2","task3","new_task"]
-- The new element is inserted just before the last element (task3)
SELECT JSON_ARRAY_INSERT('["task1", "task2", "task3"]'::VARIANT, -1, '"new_task"'::VARIANT);
-[ RECORD 1 ]-----------------------------------
json_array_insert('["task1", "task2", "task3"]'::VARIANT, - 1, '"new_task"'::VARIANT): ["task1","task2","new_task","task3"]
-- Since the negative index exceeds the array’s length, the new element is inserted at the beginning
SELECT JSON_ARRAY_INSERT('["task1", "task2", "task3"]'::VARIANT, -6, '"new_task"'::VARIANT);
-[ RECORD 1 ]-----------------------------------
json_array_insert('["task1", "task2", "task3"]'::VARIANT, - 6, '"new_task"'::VARIANT): ["new_task","task1","task2","task3"]
- JSON_ARRAY_INTERSECTION: Returns the common elements between two JSON arrays.
-- Find the intersection of two JSON arrays
SELECT json_array_intersection('["Electronics", "Books", "Toys"]'::JSON, '["Books", "Fashion", "Electronics"]'::JSON);
-[ RECORD 1 ]-----------------------------------
json_array_intersection('["Electronics", "Books", "Toys"]'::VARIANT, '["Books", "Fashion", "Electronics"]'::VARIANT): ["Electronics","Books"]
-- Find the intersection of the result from the first query with a third JSON array using an iterative approach
SELECT json_array_intersection(
json_array_intersection('["Electronics", "Books", "Toys"]'::JSON, '["Books", "Fashion", "Electronics"]'::JSON),
'["Electronics", "Books", "Clothing"]'::JSON
);
-[ RECORD 1 ]-----------------------------------
json_array_intersection(json_array_intersection('["Electronics", "Books", "Toys"]'::VARIANT, '["Books", "Fashion", "Electronics"]'::VARIANT), '["Electronics", "Books", "Clothing"]'::VARIANT): ["Electronics","Books"]
- JSON_ARRAY_OVERLAP: Checks if there is any overlap between two JSON arrays and returns true if there are common elements; otherwise, it returns false.
SELECT json_array_overlap(
'["apple", "banana", "cherry"]'::JSON,
'["banana", "kiwi", "mango"]'::JSON
);
-[ RECORD 1 ]-----------------------------------
json_array_overlap('["apple", "banana", "cherry"]'::VARIANT, '["banana", "kiwi", "mango"]'::VARIANT): true
SELECT json_array_overlap(
'["grape", "orange"]'::JSON,
'["apple", "kiwi"]'::JSON
);
-[ RECORD 1 ]-----------------------------------
json_array_overlap('["grape", "orange"]'::VARIANT, '["apple", "kiwi"]'::VARIANT): false
- JSON_ARRAY_REDUCE: Reduces a JSON array to a single value by applying a specified Lambda expression.
SELECT JSON_ARRAY_REDUCE(
[2, 3, 4]::JSON,
(acc, d) -> acc::Int * d::Int
);
-[ RECORD 1 ]-----------------------------------
json_array_reduce([2, 3, 4]::VARIANT, (acc, d) -> acc::Int32 * d::Int32): 24
- JSON_ARRAY_TRANSFORM (Aliases: JSON_ARRAY_APPLY and JSON_ARRAY_MAP): Transforms each element of a JSON array using a specified transformation Lambda expression.
SELECT JSON_ARRAY_TRANSFORM(
[1, 2, 3, 4]::JSON,
data -> (data::Int * 10)
);
-[ RECORD 1 ]-----------------------------------
json_array_transform([1, 2, 3, 4]::VARIANT, data -> data::Int32 * 10): [10,20,30,40]
- JSON_OBJECT_PICK: Creates a new JSON object containing only the specified keys from the input JSON object. If a specified key doesn’t exist in the input object, it is omitted from the result.
-- Pick a single key:
SELECT json_object_pick('{"a":1,"b":2,"c":3}'::VARIANT, 'a');
-- Result: {"a":1}
-- Pick multiple keys:
SELECT json_object_pick('{"a":1,"b":2,"d":4}'::VARIANT, 'a', 'b');
-- Result: {"a":1,"b":2}
-- Pick with non-existent key (non-existent keys are ignored):
SELECT json_object_pick('{"a":1,"b":2,"d":4}'::VARIANT, 'a', 'c');
-- Result: {"a":1}
- JSON_OBJECT_DELETE: Deletes specified keys from a JSON object and returns the modified object. If a specified key doesn’t exist in the object, it is ignored.
-- Delete a single key:
SELECT json_object_delete('{"a":1,"b":2,"c":3}'::VARIANT, 'a');
-- Result: {"b":2,"c":3}
-- Delete multiple keys:
SELECT json_object_delete('{"a":1,"b":2,"d":4}'::VARIANT, 'a', 'c');
-- Result: {"b":2,"d":4}
-- Delete a non-existent key (key is ignored):
SELECT json_object_delete('{"a":1,"b":2}'::VARIANT, 'x');
-- Result: {"a":1,"b":2}
Subscribe to our newsletter
Stay informed on feature releases, product roadmap, support, and cloud offerings!

