


A few weeks ago, during the yearly conferences of Databricks and Snowflake, AI was getting a lot of attention, but the progress in data lakes and data warehouses was also significant because data is fundamental. Apache Iceberg emerged as a prominent solution for data lakes, and Databricks unveiled UniForm to better handle Apache Iceberg and Hudi table formats from Delta data. Meanwhile, Snowflake made timely updates to Iceberg Tables, aiming to eliminate data silos.
One of the significant new features that Databend has been working on in recent months is supporting the reading of data in Apache Iceberg table format. Though it's still a work in progress, they have made good progress so far.
This article is intended to give you a preview of this new capability by demonstrating how to use Databend to mount and query an Iceberg Catalog. We will cover the core concepts of Iceberg and table formats while also introducing Databend's solutions, including its ability to handle multiple data catalogs and the implementation of IceLake in Rust from scratch. As part of the demonstration, a comprehensive workshop will be provided, so you can try it out yourself.
What is Apache Iceberg?
An increasing amount of data is now moving to the cloud and being stored in object storage. However, this setup may not fully meet the demands of modern analytics. There are two key issues to address: First, how to organize data in a more structured manner, achieving a more organized data storage approach. Second, how to provide users with broader consistency guarantees, necessary schema information, and advanced features that cater to the requirements of modern analytics workloads.
Data lakes often focus on addressing and resolving the first issue, while table formats are dedicated to providing solutions for the second one.
Apache Iceberg is a high-performance open table format designed for large-scale analytics workloads. It is known for its simplicity and reliability. It supports various query engines like Spark, Trino, Flink, Presto, Hive, and Impala. One of its killer features includes full schema evolution, time travel, and rollback capabilities. Additionally, Apache Iceberg's data partitioning and well-defined data structures make concurrent access to data sources more secure, reliable, and convenient.
If you're interested in Iceberg we recommend reading Docker Spark And Iceberg: The Fastest Way To Try Iceberg!.
Table Format
Table Format is a specification for storing data using a collection of files. It consists of definitions for the following three parts:
- How to store data in files
- How to store metadata for related files
- How to store metadata for the table itself
Table format files are usually stored in underlying storage services such as HDFS, S3 or GCS, and are accessed by upper-level data warehouses such as Databend and Snowflake. Compared to CSV or Parquet, table format offers a standardized and structured data definition in tabular form, enabling its usage without the need to load it into a data warehouse.
Although there are strong competitors like Delta Lake and Apache Hudi in the field of table formats, this article focuses on Apache Iceberg. Let's take a look at its underlying file organization structure together.

The figures above illustrate "s0" and "s1," representing snapshots of the table. A snapshot captures the table's state at specific points in time. Each commit results in a snapshot, and each snapshot is associated with an inventory list (manifest list). The inventory list can hold multiple addresses of manifest files, along with statistical information, including path and partition range. The manifest file serves to record the addresses and statistical details of data files generated from current operations, such as maximum/minimum values and number of rows per column.
Multiple Catalog
To integrate Databend with Iceberg, the first step is to add the Multiple Catalog capability to Databend. The Multiple Catalog enables the data that was previously managed by other data analysis systems to be mounted onto Databend.
From the very beginning, Databend's objective has been to function as a cloud-native OLAP data warehouse, with a focus on addressing the complexities of handling multiple data sources. In Databend, data is structured into three layers: catalog -> database -> table. The catalog represents the highest level and encompasses all databases and tables.
Based on this foundation, our team designed and implemented support for Hive and Iceberg data catalogs, providing various mounting forms such as configuration files and
CREATE CATALOG
To mount Iceberg Catalog located in S3, simply execute the following SQL statement:
CREATE CATALOG iceberg_ctl
TYPE=ICEBERG
CONNECTION=(
URL='s3://warehouse/path/to/db'
AWS_KEY_ID='admin'
AWS_SECRET_KEY='password'
ENDPOINT_URL='your-endpoint-url'
);
IceLake - A Pure Rust Implementation of Apache Iceberg
Although the Rust ecosystem has seen the rise of many new projects related to databases and big data analysis in recent years, there is still a notable absence of mature Apache Iceberg bindings in Rust. This has presented significant challenges for Databend when it comes to integrating with Iceberg.
IceLake, supported and initiated by Databend Labs, aims to overcome the challenges and establish an open ecosystem where:
- Users can read/write iceberg tables from ANY storage services like s3, gcs, azblob, hdfs and so on.
- ANY databases can integrate with to facilitate reading and writing of iceberg tables.
icelake - Provides NATIVE support transmute between s.
arrow - Provides bindings so that other languages can work with iceberg tables powered by Rust core.
Currently, IceLake only supports reading data (in Parquet format) from Apache Iceberg storage services. The design and implementation of Databend's Iceberg catalog is supported by Icelake and has been validated through integration with Databend.
In addition, we have also collaborated with the Iceberg community to initiate and participate in the iceberg-rust project. The project aims to contribute Iceberg-related implementations from IceLake upstream, and the first version is currently under intense development.
Workshop: Experience Iceberg with Databend
In this workshop, we will demonstrate how to prepare data in Iceberg table format and mount it onto Databend as a Catalog, and perform some basic queries. Relevant files and configurations can be found at PsiACE/databend-workshop.
If you already have data that conforms to the Iceberg table format stored in a storage service supported by OpenDAL, we recommend using Databend Cloud so that you can skip the tedious process of service deployment and data preparation, and easily get started with the Iceberg Catalog.
Starting Services
To simplify the service deployment and data preparation issues of Iceberg, we will be using Docker and Docker Compose. You need to install these components first, and then write the
docker-compose.yml
version: '3'
services:
spark-iceberg:
image: tabulario/spark-iceberg
container_name: spark-iceberg
build: spark/
networks:
iceberg_net:
depends_on:
- rest
- minio
volumes:
- ./warehouse:/home/iceberg/warehouse
- ./notebooks:/home/iceberg/notebooks/notebooks
environment:
- AWS_ACCESS_KEY_ID=admin
- AWS_SECRET_ACCESS_KEY=password
- AWS_REGION=us-east-1
ports:
- 8888:8888
- 8080:8080
- 10000:10000
- 10001:10001
rest:
image: tabulario/iceberg-rest
container_name: iceberg-rest
networks:
iceberg_net:
ports:
- 8181:8181
environment:
- AWS_ACCESS_KEY_ID=admin
- AWS_SECRET_ACCESS_KEY=password
- AWS_REGION=us-east-1
- CATALOG_WAREHOUSE=s3://warehouse/
- CATALOG_IO__IMPL=org.apache.iceberg.aws.s3.S3FileIO
- CATALOG_S3_ENDPOINT=http://minio:9000
minio:
image: minio/minio
container_name: minio
environment:
- MINIO_ROOT_USER=admin
- MINIO_ROOT_PASSWORD=password
- MINIO_DOMAIN=minio
networks:
iceberg_net:
aliases:
- warehouse.minio
ports:
- 9001:9001
- 9000:9000
command: ['server', '/data', '--console-address', ':9001']
mc:
depends_on:
- minio
image: minio/mc
container_name: mc
networks:
iceberg_net:
environment:
- AWS_ACCESS_KEY_ID=admin
- AWS_SECRET_ACCESS_KEY=password
- AWS_REGION=us-east-1
entrypoint: >
/bin/sh -c "
until (/usr/bin/mc config host add minio http://minio:9000 admin password) do echo '...waiting...' && sleep 1; done;
/usr/bin/mc rm -r --force minio/warehouse;
/usr/bin/mc mb minio/warehouse;
/usr/bin/mc policy set public minio/warehouse;
tail -f /dev/null
"
networks:
iceberg_net:
In the above configuration file, we use MinIO as the underlying storage, Iceberg provides table formatting capabilities, and
spark-iceberg
Next, we start all services in the directory corresponding to the
docker-compose.yml
docker-compose up -d
Data Preparation
In this workshop, we plan to use the NYC Taxis dataset (data on taxi rides in New York City), which is already built into
spark-iceberg
First, enable
pyspark-notebook
docker exec -it spark-iceberg pyspark-notebook
Next, we can start Jupyter Notebook at http://localhost:8888:
Here we need to run the following code to implement the data conversion operation:
df = spark.read.parquet("/home/iceberg/data/yellow_tripdata_2021-04.parquet")
df.write.saveAsTable("nyc.taxis", format="iceberg")
The first line will read the Parquet data and the second line will convert it into Iceberg format.
To verify that the data has been successfully converted, we can access the MinIO instance located at http://localhost:9001 and notice that the data is managed according to the Iceberg underlying file organization described earlier.
Deploying Databend
Here we will manually deploy a single-node Databend service. The overall deployment process can refer to Docs | Deploying a Standalone Databend, and some details that need attention are as follows:
-
First, prepare the relevant directories for logs and meta data.
sudo mkdir /var/log/databend
sudo mkdir /var/lib/databend
sudo chown -R $USER /var/log/databend
sudo chown -R $USER /var/lib/databend -
Secondly, because the default
has been occupied byadmin_api_address, it is necessary to editspark-icebergto make some modifications to avoid conflicts:databend-query.tomladmin_api_address = "0.0.0.0:8088" -
In addition, according to Docs | Configuring Admin Users, we also need to configure administrator users. Since this is just a workshop, we choose the simplest way by simply uncommenting
field and root user:[[query.users]][[query.users]
name = "root"
auth_type = "no_password" -
Because we deployed MinIO locally without setting certificate encryption, we need to use insecure HTTP protocol to load data. Therefore, it is necessary to change the configuration file of
in order to allow this behavior. Please try your best not enable it in production services:databend-query.toml...
[storage]
...
allow_insecure = true
...
The next step is to start up Databend:
./scripts/start.sh
We strongly recommend using BendSQL as a client tool for accessing Databand. Of course, we also support various access methods such as MySQL Client and HTTP API.
Mounting Iceberg Catalog
According to the previous configuration file, you only need to execute the following SQL statement to mount the Iceberg Catalog.
CREATE CATALOG iceberg_ctl
TYPE=ICEBERG
CONNECTION=(
URL='s3://warehouse/'
AWS_KEY_ID='admin'
AWS_SECRET_KEY='password'
ENDPOINT_URL='http://localhost:9000'
);
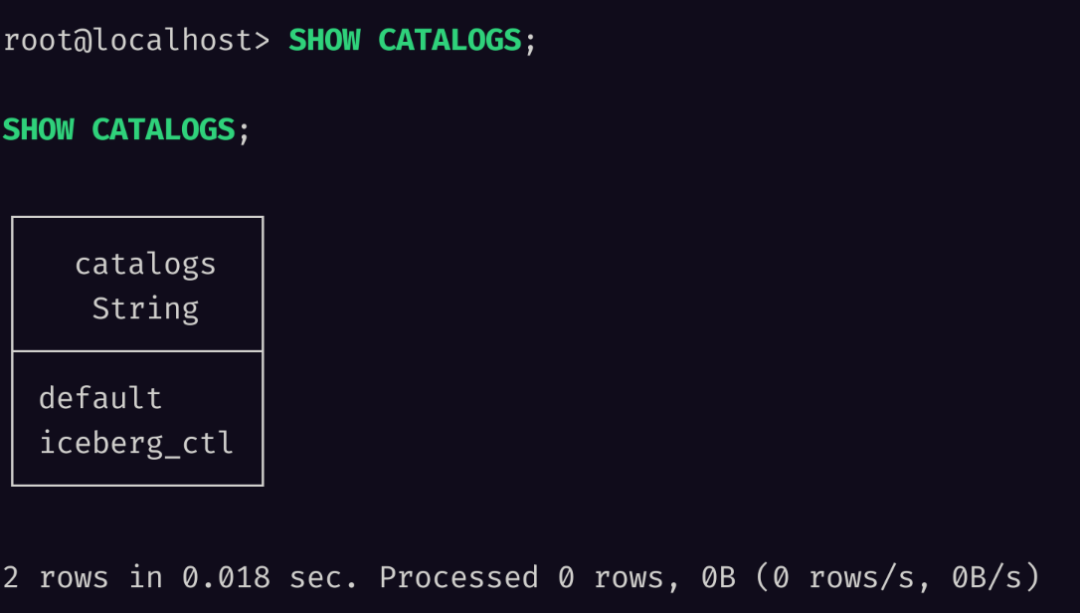
To verify the mounting, we can execute
SHOW CATALOGS
Of course, Databend also supports
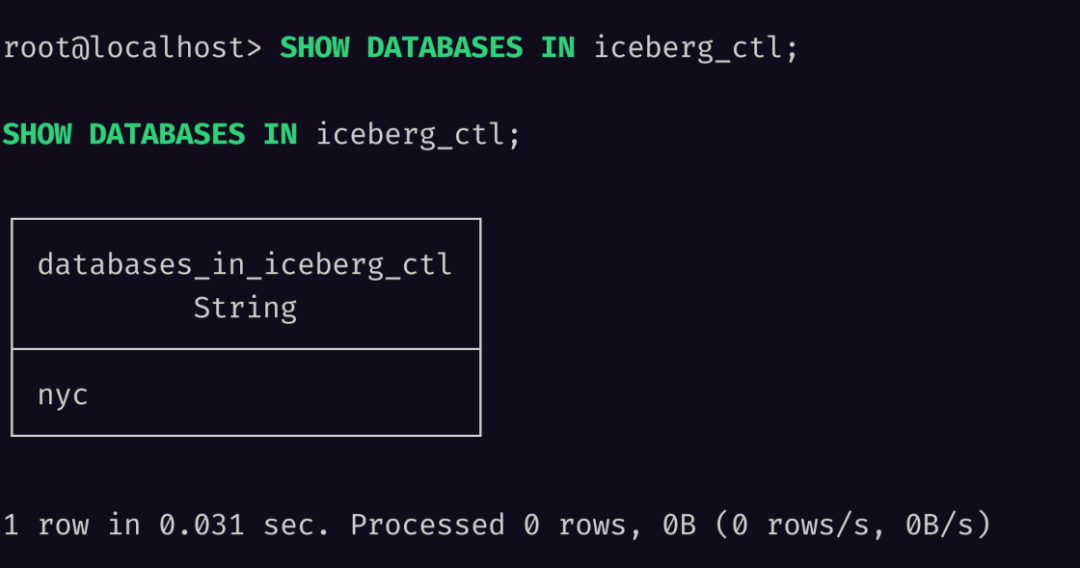
SHOW DATABASES
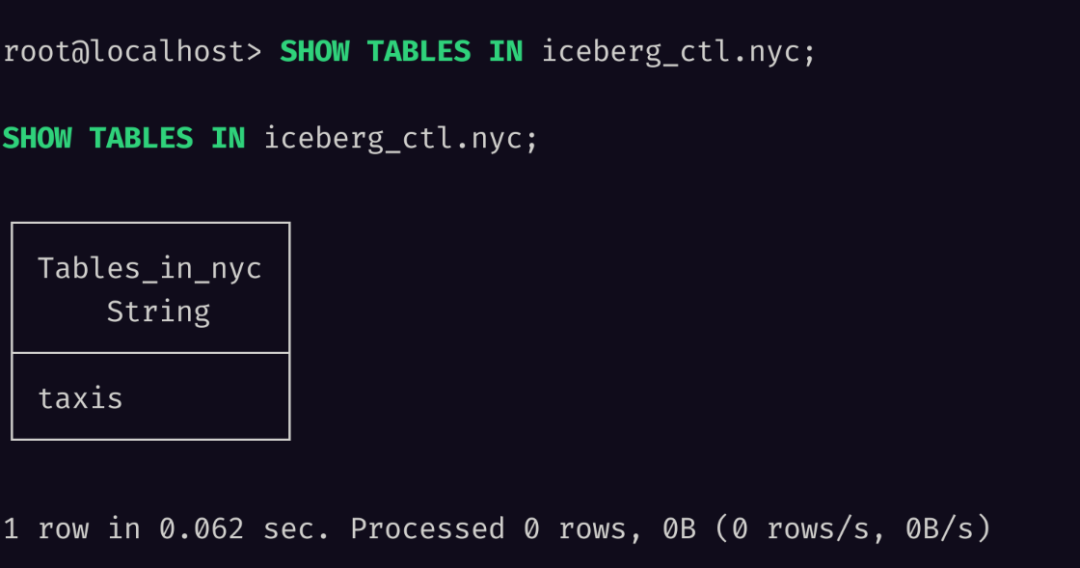
SHOW TABLES
nyc.taxis
Running Queries
Now that the data has been mounted, let's try some simple queries:
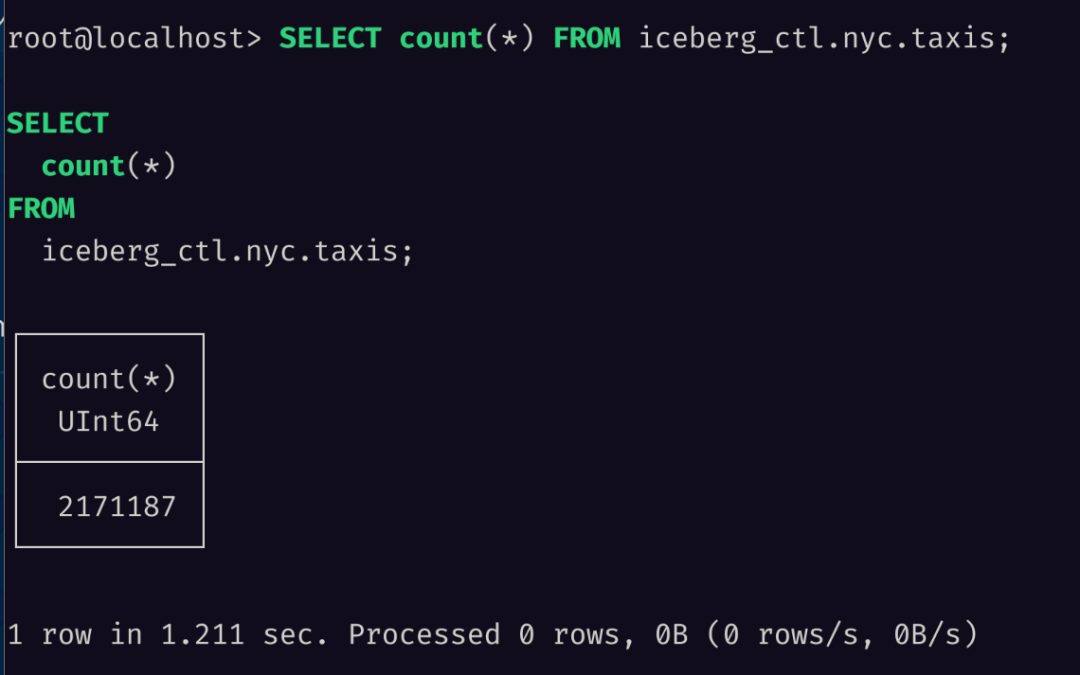
Firstly, let's count the number of rows in the data. We can see that a total of 2 million rows have been mounted to Databend:
SELECT count(*) FROM iceberg_ctl.nyc.taxis;
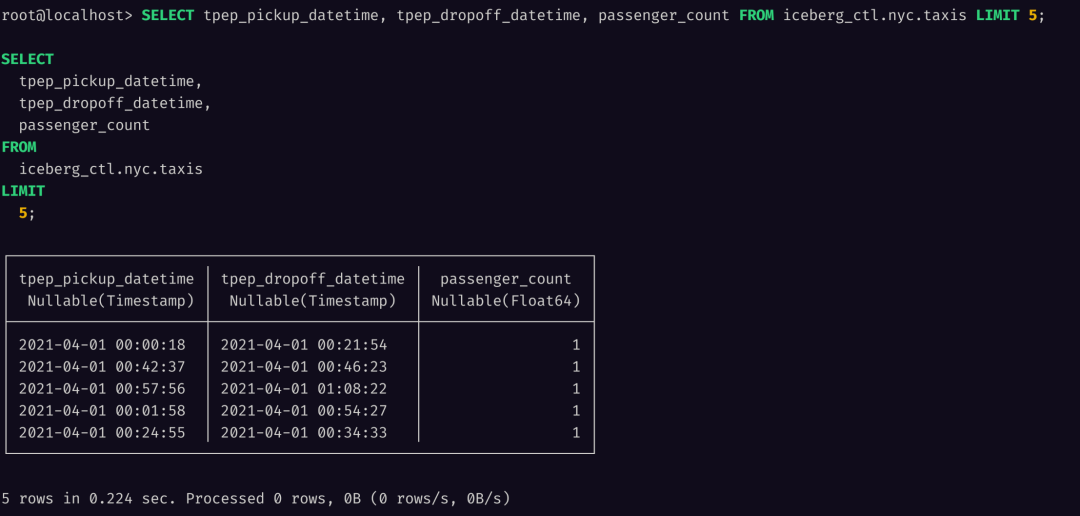
Let's try to retrieve some data from a few columns:
SELECT tpep_pickup_datetime, tpep_dropoff_datetime, passenger_count FROM iceberg_ctl.nyc.taxis LIMIT 5;
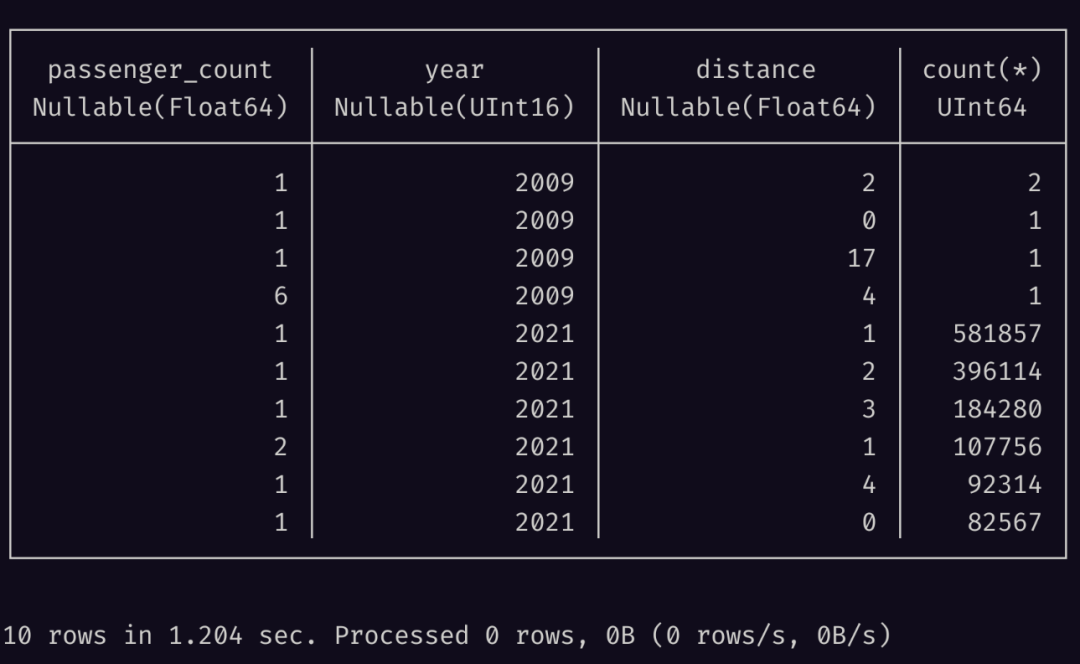
The following query can help us explore the correlation between passenger count and travel distance. Here we only take 10 results:
SELECT
passenger_count,
to_year(tpep_pickup_datetime) AS year,
round(trip_distance) AS distance,
count(*)
FROM
iceberg_ctl.nyc.taxis
GROUP BY
passenger_count,
year,
distance
ORDER BY
year,
count(*) DESC
LIMIT
10;
Summary
In this article, we introduced Apache Iceberg table format and Databend solution for it, and provided a workshop for everyone to gain some hands-on experience.
Currently, Databend only provide catalog mounting capability for Iceberg Integration, but it can handle some basic query processing tasks. We also welcome everyone to try it out on their own interested data and provide us with feedback.
Subscribe to our newsletter
Stay informed on feature releases, product roadmap, support, and cloud offerings!

