


Since its official release in 2015, Rust has quickly attracted the attention of a large number of developers and tech companies. Initiated as an open-source project by Mozilla, Rust aims to create a highly efficient, memory-safe, and user-friendly programming language. With its innovative memory management system, concurrency model, and modern syntax, Rust not only addresses some challenges in traditional languages like C and C++, but also provides developers with a fresh programming experience.
Why Rust?
The rapid rise of Rust can be attributed to its unique advantages. First and foremost, Rust emphasizes safety, utilizing a memory management mechanism that avoids common errors like dangling pointers and memory leaks. Secondly, it delivers performance comparable to low-level languages without sacrificing speed, particularly excelling in high-performance and high-concurrency scenarios. Rust's design philosophy and technical architecture make it a significant choice for modern systems programming. Furthermore, its advantages extend beyond system-level programming, showing great potential across multiple domains, from web development to foundational software.
Our team developed Databend, an open-source, elastic, and load-aware cloud-native data lakehouse, entirely based on Rust. In fact, most of our early team members previously contributed to projects like ClickHouse, TiDB, Oceanbase, and MySQL, primarily working with C++ and Go. The company’s founder and CEO, BohuTANG, even created a vectorized query engine prototype (VectorSQL) in Go before establishing Databend.
However, during actual testing, we discovered that Go could not meet the high-performance demands of databases due to issues like garbage collection. At this point, we turned to Rust. With its ownership and borrowing model and lifetime guarantees, Rust ensures memory safety without relying on garbage collection. Additionally, Rust's compile-time checks ensure thread safety, preventing null pointers, buffer overflows, and other issues, significantly reducing runtime crashes. In contrast, C++ requires manual memory management, which is prone to memory leaks and undefined behaviors.
Thanks to zero-cost abstractions, Rust's advanced features, such as generics and pattern matching, introduce no runtime overhead. Through compile-time checks, Rust avoids data races, provides a type-safe and efficient concurrency model, and natively supports asynchronous programming. Compared to C++, Rust's tooling enhances development efficiency.
In summary, Rust strikes a balance between safety, performance, and developer experience, making it especially suitable for high-performance data warehouse scenarios like Databend. It meets the extreme demands of low-level performance while simplifying development and minimizing potential issues through memory safety and concurrency models. These unique strengths make Rust the ideal language for building cloud-native high-performance systems. Many companies developing Serverless DB solutions now use Rust for core development and Go for business logic.
High-Performance Practices with Rust
Next, let's see how we leveraged Rust's unique features to significantly improve the scalability, stability, and performance of our database system.
Dispatch

Rust's Trait is an abstraction for type behavior, similar to Java's interface. When the system invokes a Trait, we need to determine which specific implementation and type to use, typically through two kinds of dispatch: static and dynamic.
-
Static Dispatch: This resolves the concrete implementation at compile time (as shown in the left diagram). It has no runtime overhead and uses monomorphization during compilation to generate specialized code for each type. Rust implements static dispatch through generics and trait constraints. Its advantage lies in high performance, as the function’s type and method are determined at compile time, avoiding runtime overhead. Rust’s type system validates all trait constraints during compilation to ensure the expected behavior of types. However, static dispatch has a downside: code bloat. It generates code for every concrete type during compilation, which can slow down compilation and increase the binary size. Compared to dynamic dispatch, static dispatch offers lower flexibility.
-
Dynamic Dispatch: This hides unnecessary type information to improve encapsulation and simplify implementation. It determines method calls at runtime, using virtual tables (vtables) to look up type information. While dynamic dispatch offers flexibility, it introduces additional runtime overhead.
These two methods have distinct pros and cons and are suited for different scenarios. For performance-critical components, such as database function calculations, static dispatch is recommended. For extensibility or polymorphism, dynamic dispatch is preferred.
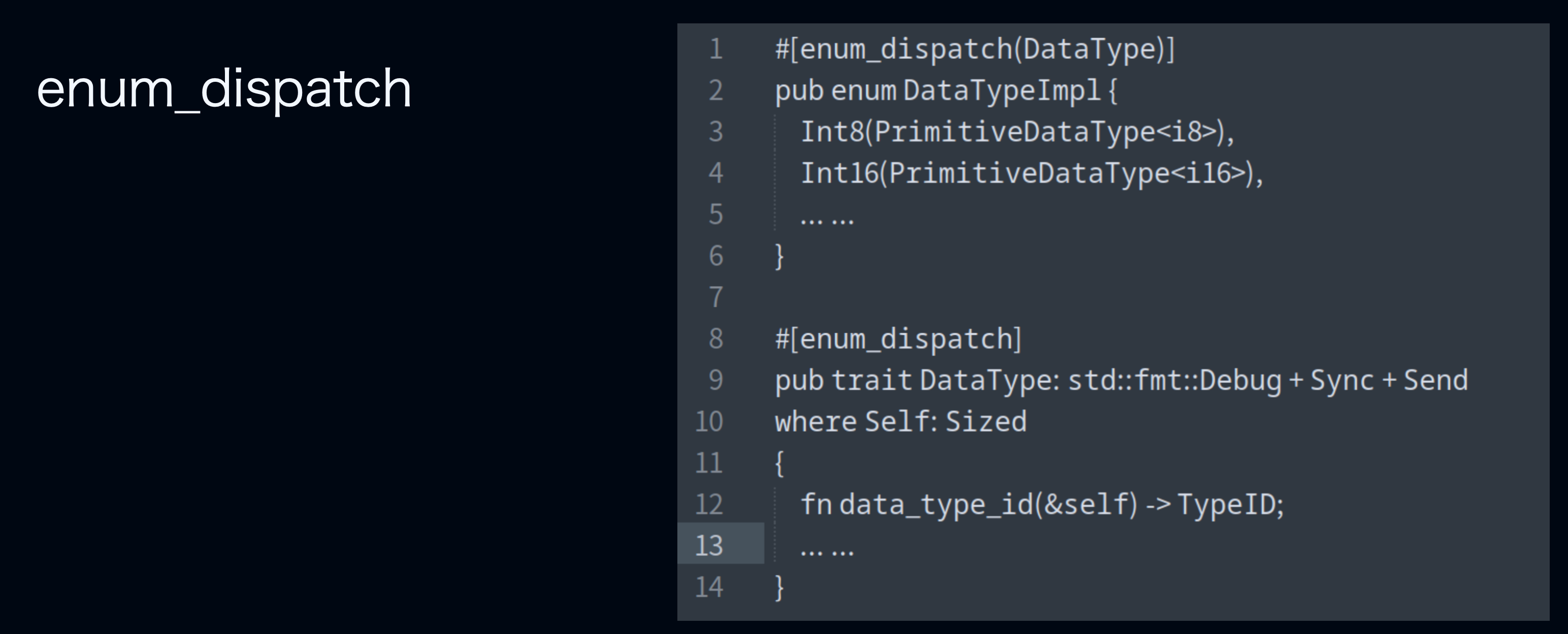
Additionally, enum_dispatch is a macro that optimizes dynamic dispatch by converting trait objects into specific composite types. During compilation, it generates specialized code for each variant of an enum to implement trait methods. This avoids runtime dispatch while retaining the flexibility of dynamic dispatch. Essentially, it is syntactic sugar and still a form of static dispatch.
Lazy Initialization
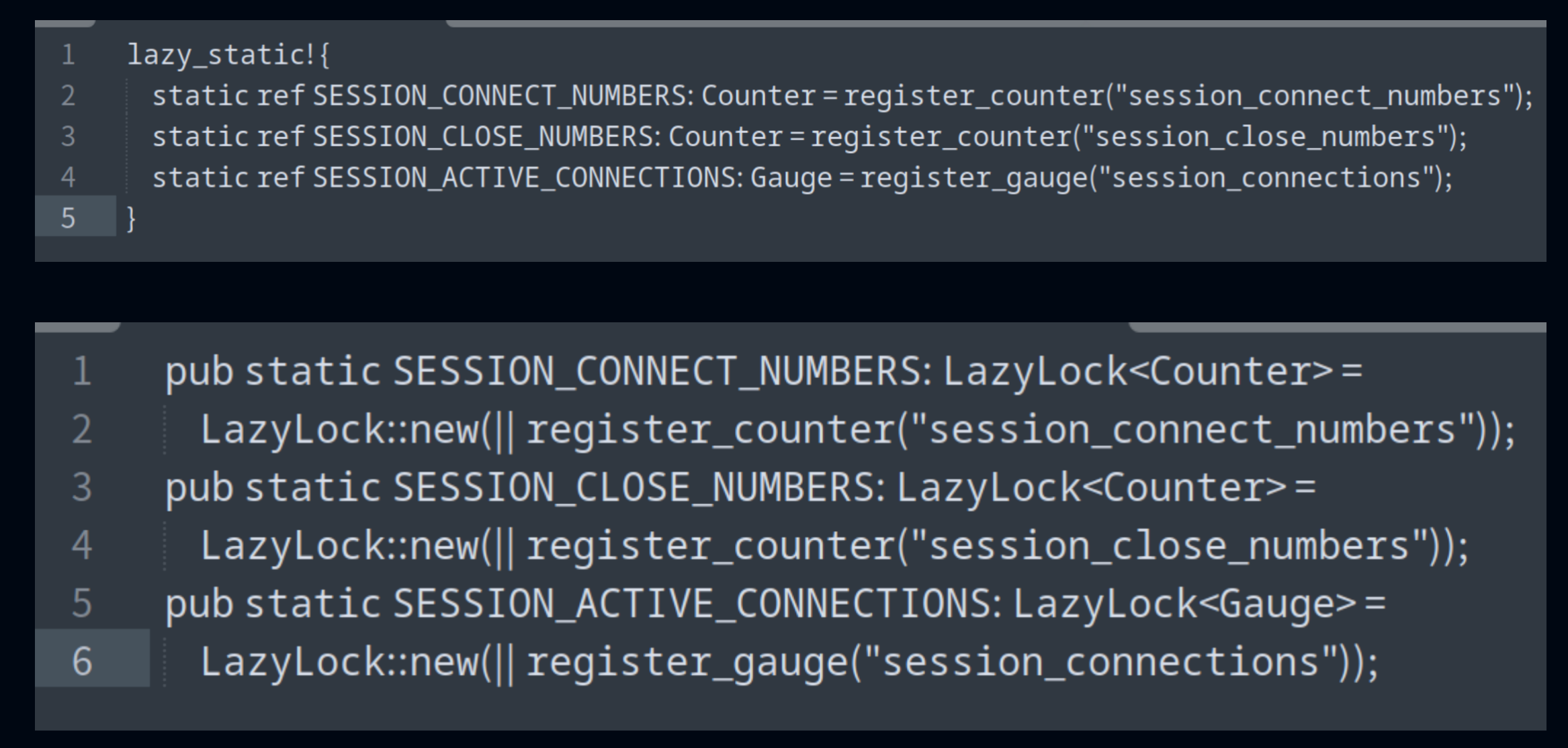
Since Rust 1.8, the Lazy lock has been stabilized. Using this method, the value of static data is initialized only during the first thread-safe access, avoiding unnecessary pre-computation or resource occupation.
Constant Evaluation
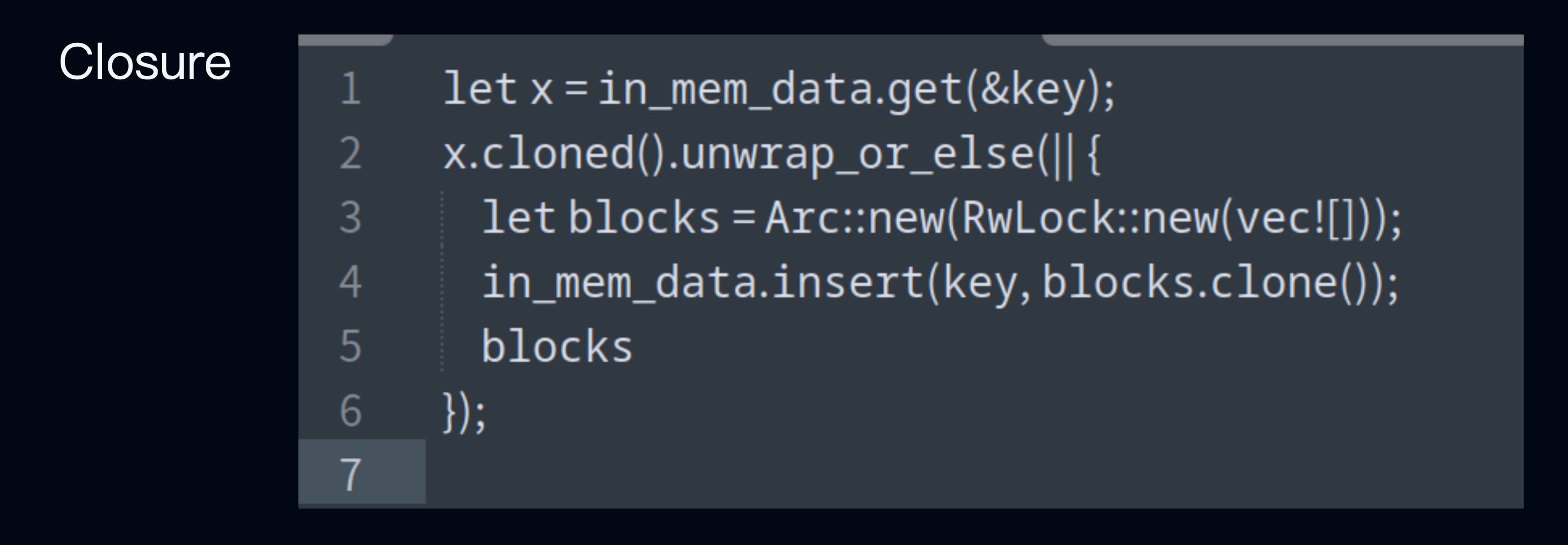
Constant evaluation refers to computing the value of an expression at compile time. In Rust, you can achieve this using closures, ensuring computations are performed only when truly necessary, thereby avoiding unnecessary overhead. When working with Result or Option, you can utilize methods provided by Rust's standard library, such as unwrap_or_else, to implement this behavior.
Inline Optimization
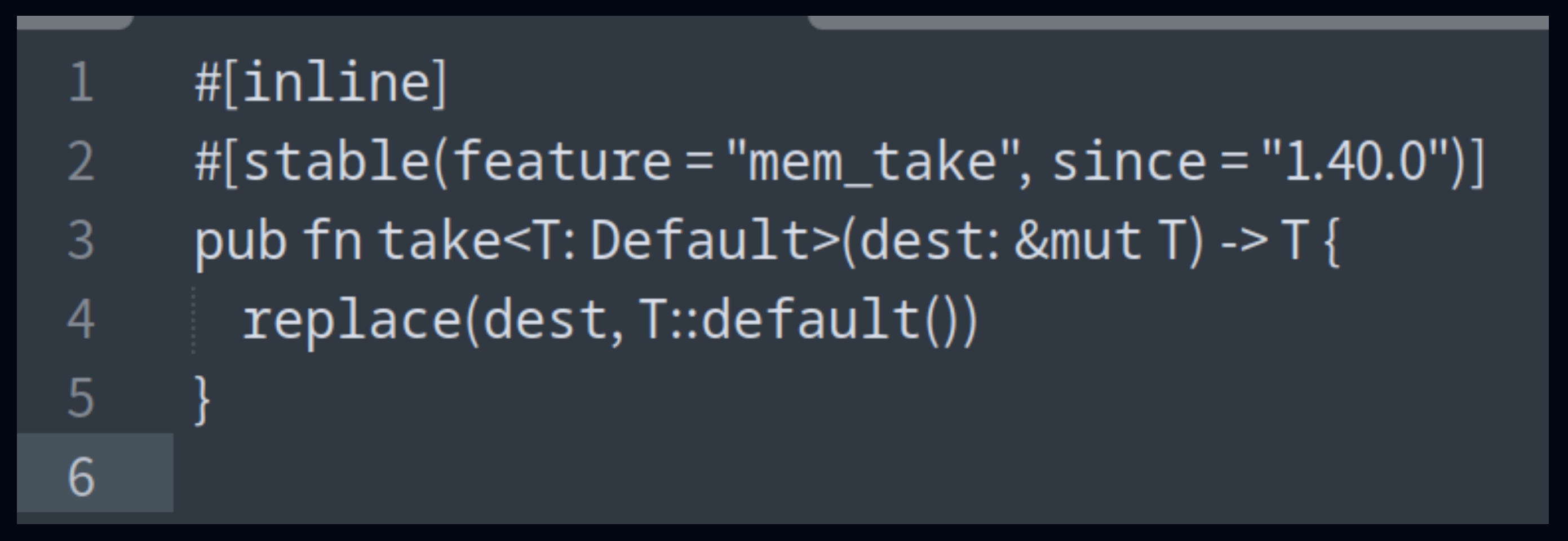
When Rust invokes a function, there are typical costs:
-
Creating a stack frame: Every function call allocates a stack frame.
-
Jump instructions: The program jumps to the function's code location and, after execution, returns to the original call site.
inline is an optimization hint that allows the compiler to replace function calls with the function body, reducing overhead. For functions on critical performance paths, such as public APIs or cross-crate implementations, adding inline can be beneficial. Rust's compiler is intelligent enough to automatically inline functions when appropriate.
The benefits of inlining include reduced function call overhead and improved performance, particularly for small, frequently called functions. However, excessive inlining can cause code bloat, slowing down compilation and increasing binary size.
Memory Management

Avoid unnecessary memory copies. For example, passing references avoids data duplication. Rust's standard library also provides methods to reduce memory allocations:
-
swap: Swaps two values without extra memory overhead.
-
replace: Replaces a variable with a new value, returning the original value.
-
take: Replaces a variable with a default value, returning the original value.
-
append: Moves data to avoid unnecessary memory copies.
Additionally, use with_capacity when declaring objects to preallocate memory and avoid frequent dynamic allocation. We recommend using iterators instead of index-based access to eliminate runtime boundary checks and enhance performance.
Concurrency
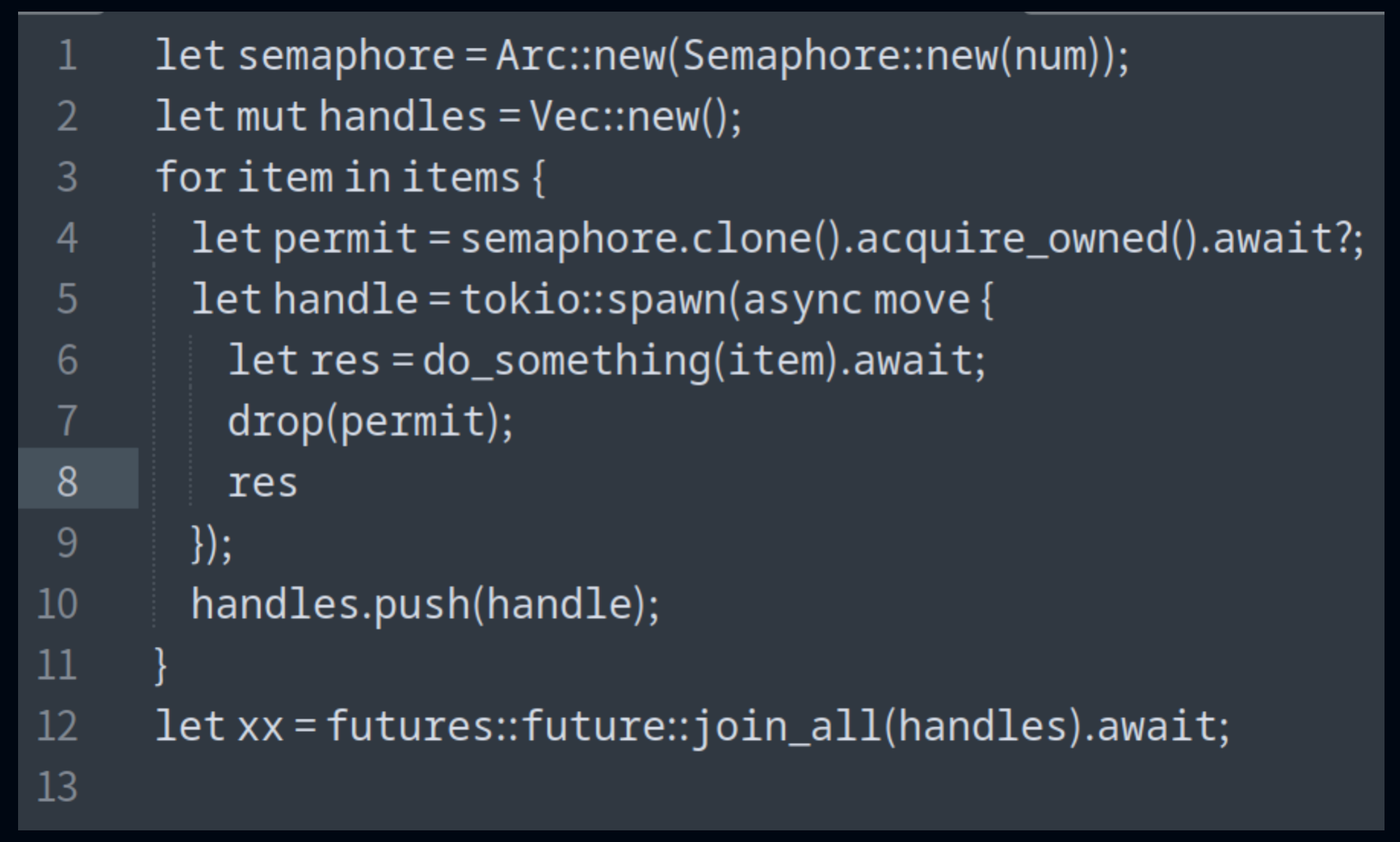
For IO-intensive scenarios, such as reading data from object storage, concurrency can improve efficiency. For example, Databend's merge sort algorithm was initially single-threaded for final sorting, which limited performance in some cases. Using the merge path method, we parallelized the merge sort process. Semaphore mechanisms can limit concurrency levels to prevent excessive parallelism.
SIMD (Single Instruction, Multiple Data)
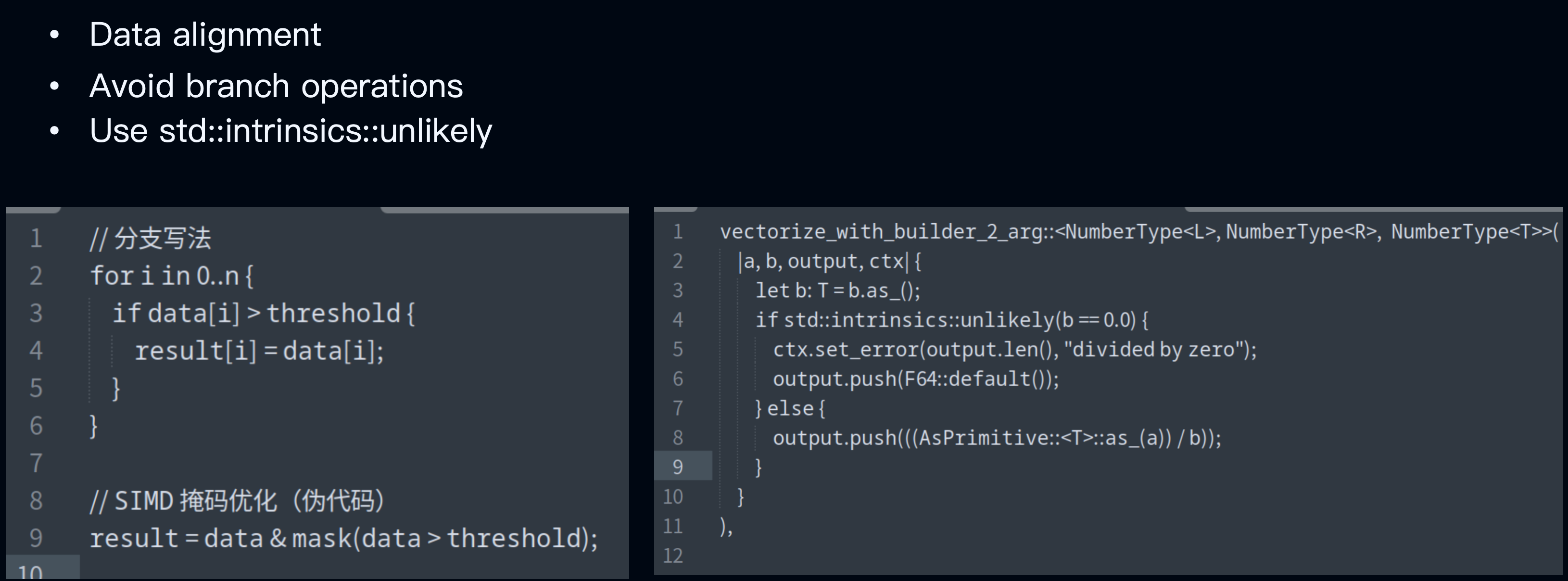
SIMD (Single Instruction Multiple Data) is a CPU optimization instruction that enables parallel processing within a single core. For example, CPUs have special registers—wide registers—such as a 256-bit register that can hold 16 16-bit integers. For operations like addition, a single instruction can process 4 sets of data in one go. In contrast, scalar methods can only process one set at a time, which clearly results in a significant performance boost.
Rust implements automatic vectorization, so developers should strive to write SIMD-friendly code. First, data alignment is essential: we need to ensure that data structures are memory-aligned to avoid performance degradation caused by misaligned memory. Second, branch operations should be avoided as they disrupt the CPU pipeline and reduce SIMD efficiency.
The example in the bottom-left of the diagram shows a branching implementation. We can convert it into SIMD-friendly code using bitwise operations. If branches are unavoidable, we can use functions like unlikely from system libraries to help the compiler optimize branch logic and reduce the performance impact of less likely code paths.
The example on the right side of the diagram shows how division is implemented in Databend, where it is necessary to check whether the divisor is 0. When such checks cannot be avoided, the unlikely function can be used to improve branch prediction and enhance SIMD performance.
Unsafe
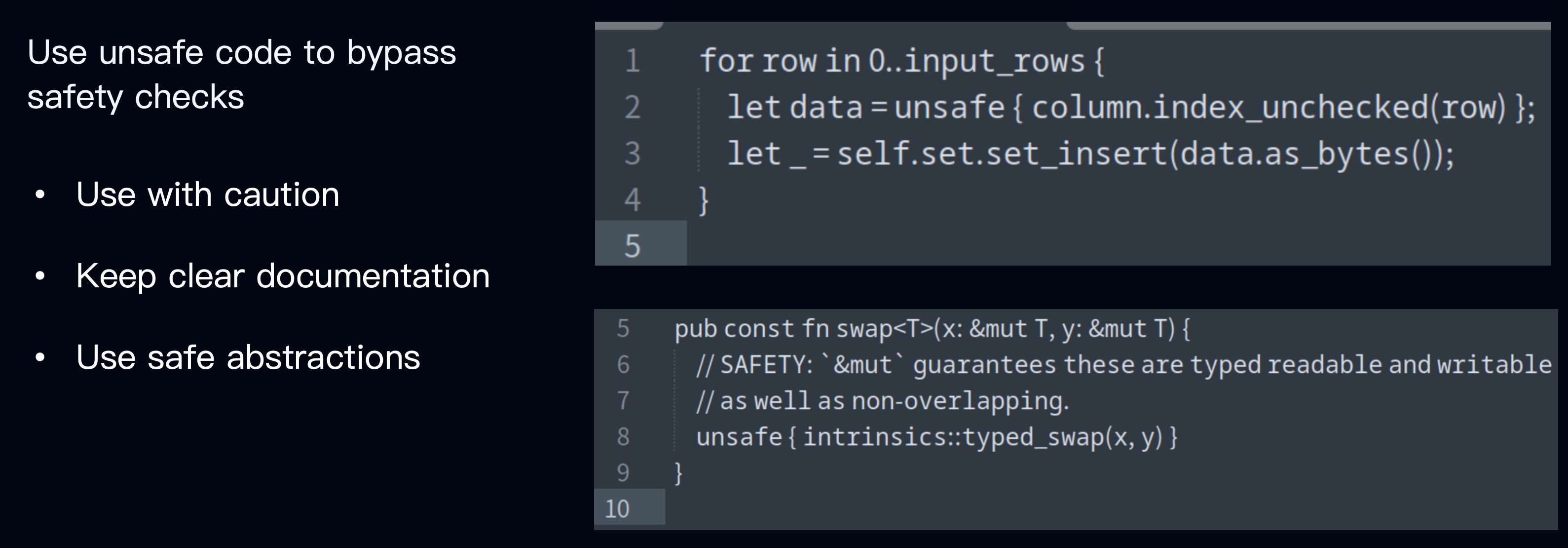
In Rust, the unsafe keyword allows bypassing the compiler's safety checks to perform more efficient low-level operations. Using unsafe code in critical paths can improve performance, but it requires ensuring the safety of these operations. If unnecessary, it is better to avoid using unsafe. If it must be used, try to limit its scope to local areas to minimize its impact on the overall codebase.
For example, in the diagram, we use the index_unchecked method to improve performance. This method skips bounds checking when accessing metadata. However, it requires external guarantees that the column is safe to access. You need to ensure it is indeed safe before using it. Additionally, you should include comments in your code to clearly document why unsafe is being used and the conditions that must be met to maintain safety. This helps other developers understand and maintain the code.
We recommend using safe abstractions to encapsulate unsafe code within safe interfaces, thereby minimizing the exposure of unsafe parts. For instance, the lower-right example refers to the swap method in the standard library. It provides a safe method externally, while its internal implementation uses unsafe code.
Performance Profiling
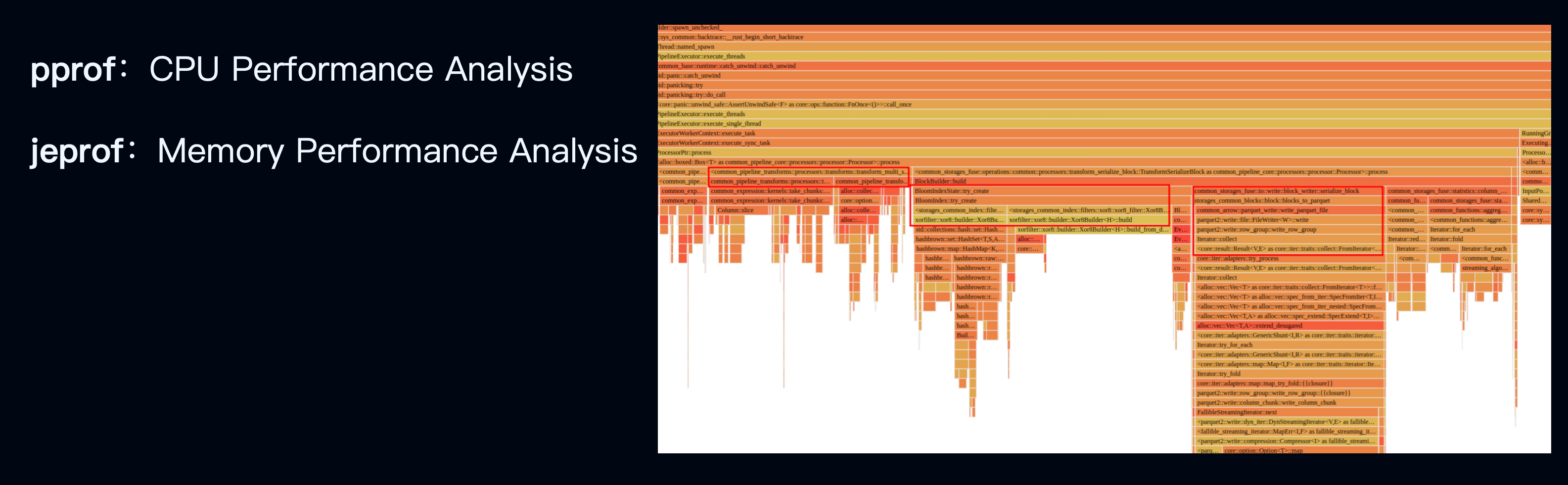
There are many tools and methods for performance profiling. Here, we mainly introduce two: pprof and jeprof. These are primarily used for CPU and memory performance analysis. Databend integrates these libraries, allowing us to leverage their capabilities to analyze our code.
On the right side of the diagram, a recluster operation in Databend is executed and analyzed using pprof, generating a flame graph. This flame graph clearly shows which parts of the operation or SQL statement are consuming resources. Based on this, we can make targeted performance optimizations.
Rewrite Big Data in Rust
Our team has a slogan: Rewrite Big Data in Rust, abbreviated as RBIR. The goal is to rewrite the entire big data ecosystem technology stack using Rust, which is known for its low memory usage, high performance, and strong safety. So far, we have implemented Hive, Iceberg, and Delta Lake in Rust. These frameworks are integrated into Databend, allowing you to read from Hive and Iceberg within Databend, and we will also support writing in the future. You can replace some of the Java-based technology stack with Rust inside Databend. After rewriting with Rust, the performance improvements have been significant. The project has already been open-sourced.
Currently, Databend contains more than 500,000 lines of Rust code, which accounts for 97.6% of the entire project codebase. The remaining part consists of Shell and Python test scripts. This demonstrates that using Rust to write such a large project for Databend three years ago was a great choice. Databend has about 8,000 stars on GitHub and 200 contributors, with more than 40% coming from external community members. The active community has continually improved Databend's features, and the user base is steadily expanding.
In addition to Databend, we also have Apache OpenDAL, an open data access layer that allows users to efficiently retrieve data from various storage services in a unified manner. OpenDAL has already graduated from the Apache Incubator and is used by multiple database vendors and enterprises. Additionally, there is the Openraft project, a high-level Raft consensus protocol written in Rust, used in Databend's Meta Service layer; Askbend, a knowledge question-answering system written in Rust that can create an SQL-based knowledge base from Markdown files; and Opensrv, jsonb, and other projects.

Since the very first day of its inception, Databend has been committed to open source. Whether you are new to Rust or databases, or an experienced database professional, you are welcome to contribute to Databend's open-source project. On Databend's GitHub, there is a section for "good first issues," which are beginner-friendly issues. For those who are new to Rust or databases, these beginner-friendly issues provide an opportunity to get involved in Databend's development process.
Subscribe to our newsletter
Stay informed on feature releases, product roadmap, support, and cloud offerings!

